AI & ML Projects
End-to-end ML/RAG work with reproducible runs: classification baselines, retrieval-augmented workflows, evaluation artifacts, and clear “what to review” paths.
Back to ProjectsRecommended review order
- RAG Mini Chat: staged build + retrieval logs.
- Next-Day Direction Classifier with RAG: time-split evaluation + model insights.
- Fake News Learning with ML: baseline -> improvements -> final evaluation.
- Finance Spending Coach: transaction analytics + budgeting + coach-style insights.
- Sales Inventory Dashboard: dashboarding + KPI reporting.
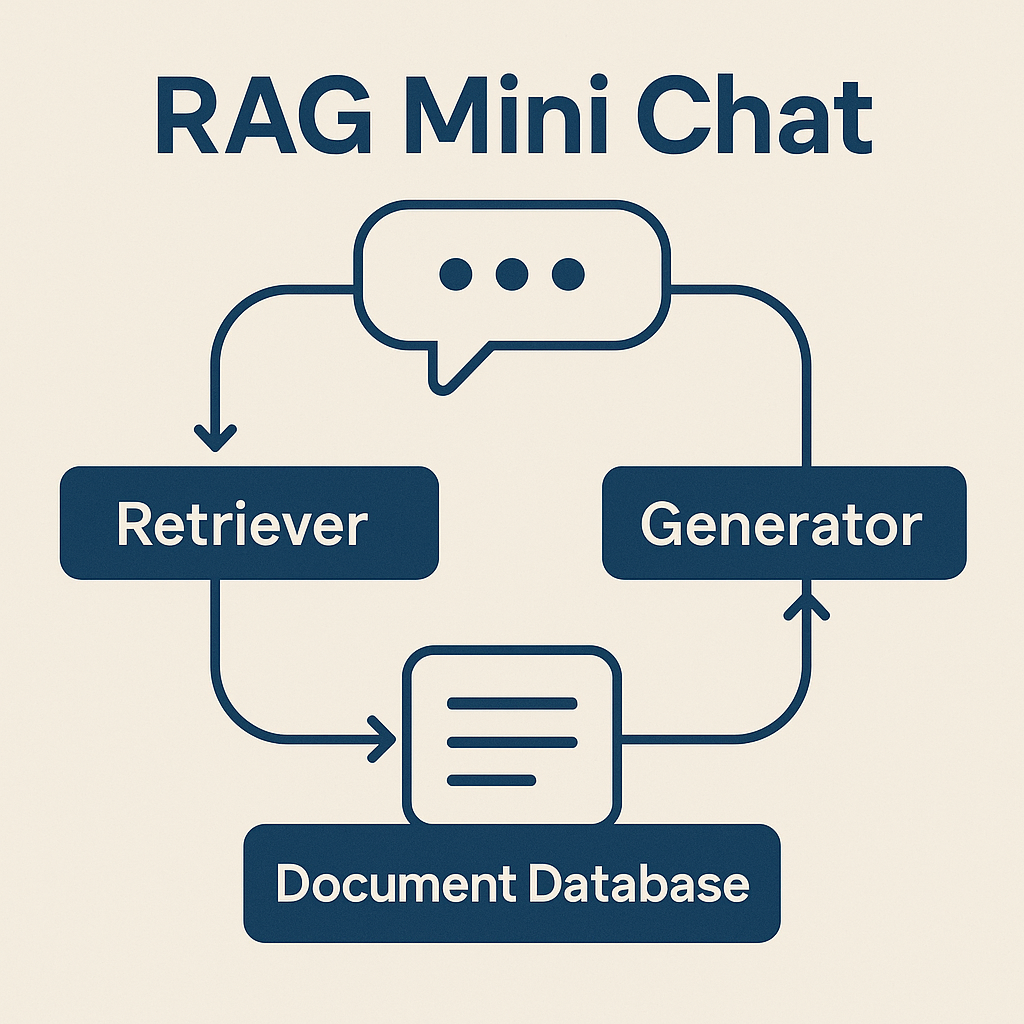
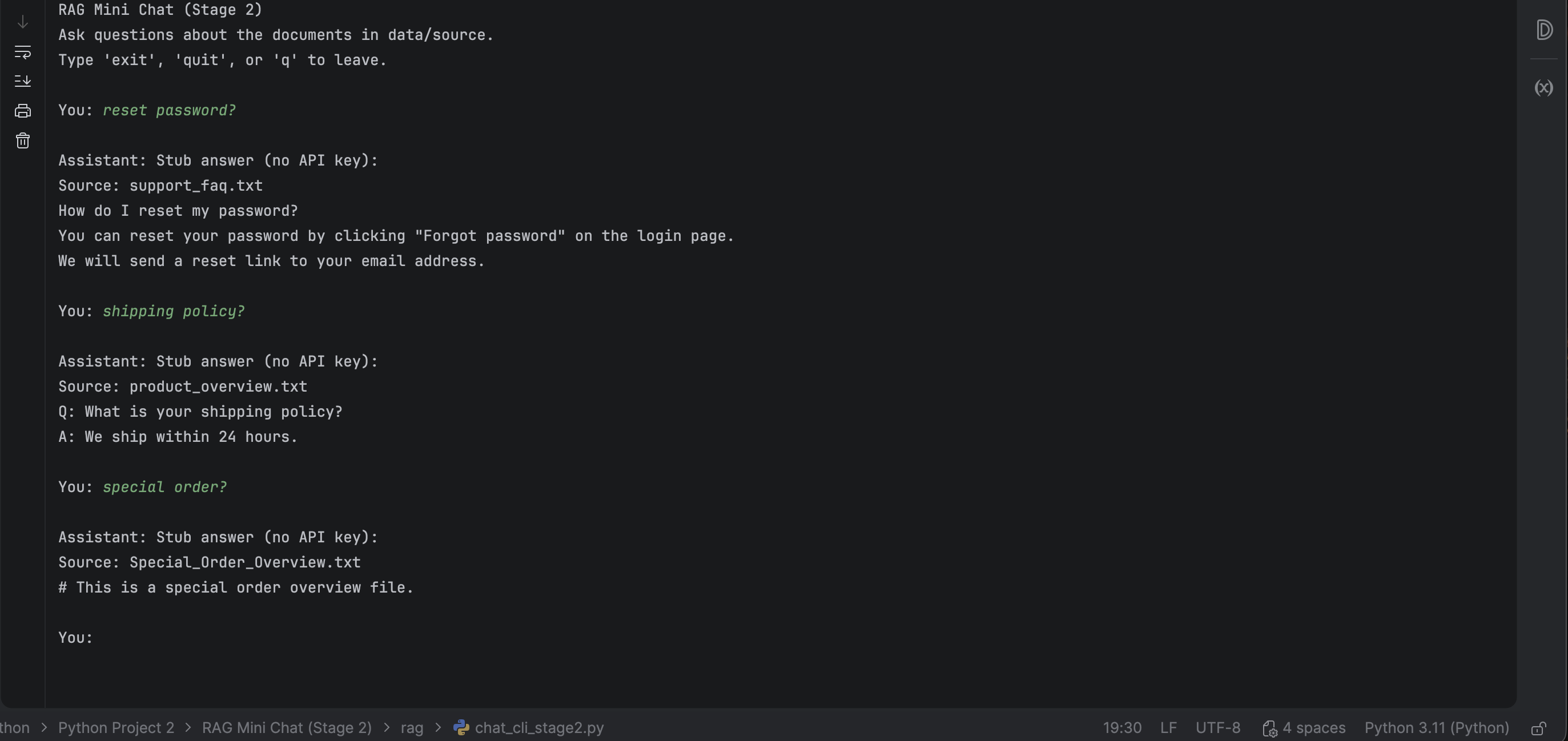
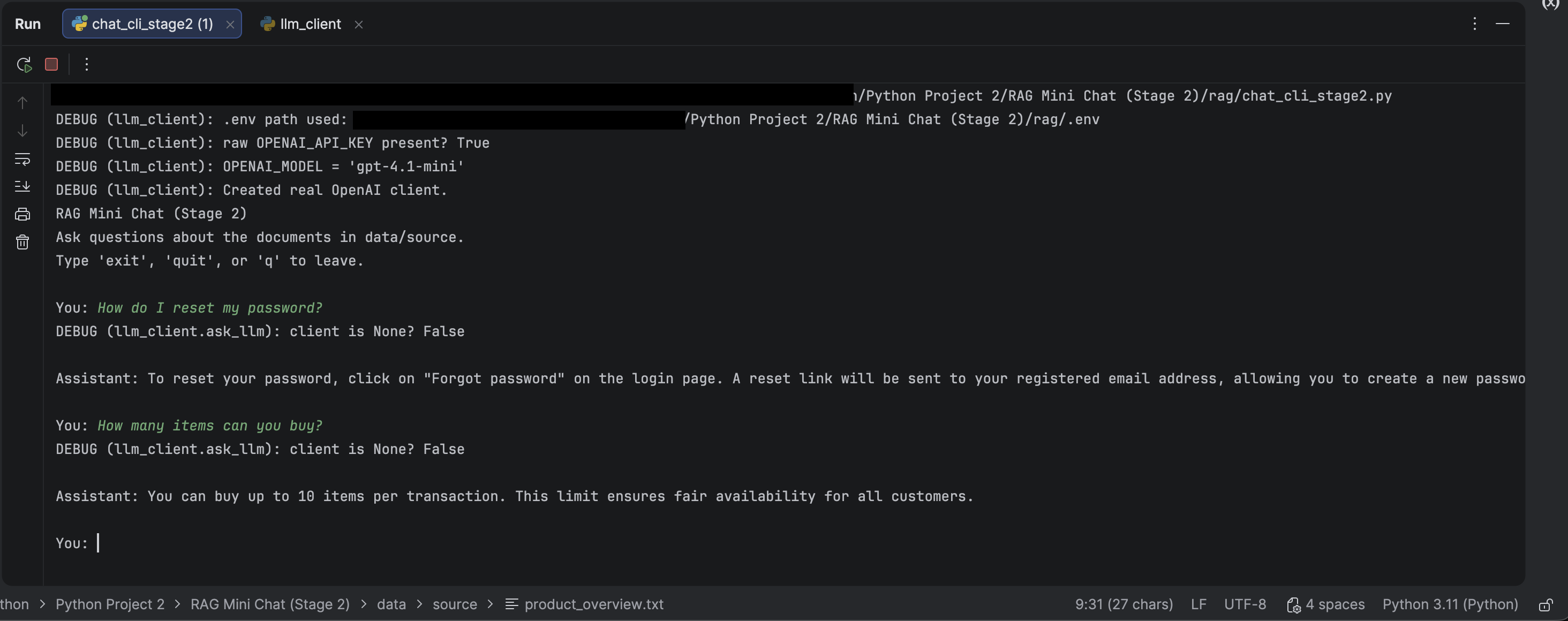
RAG Mini Chat
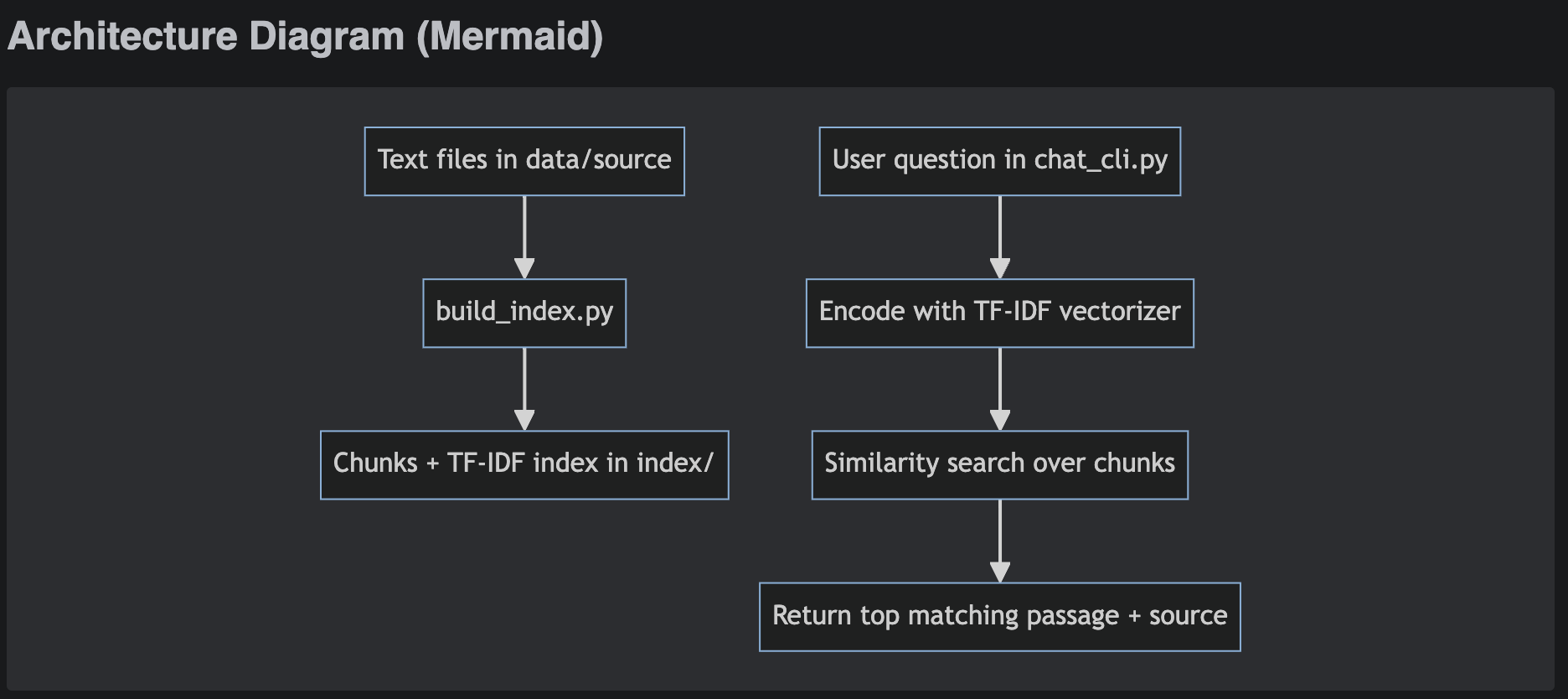
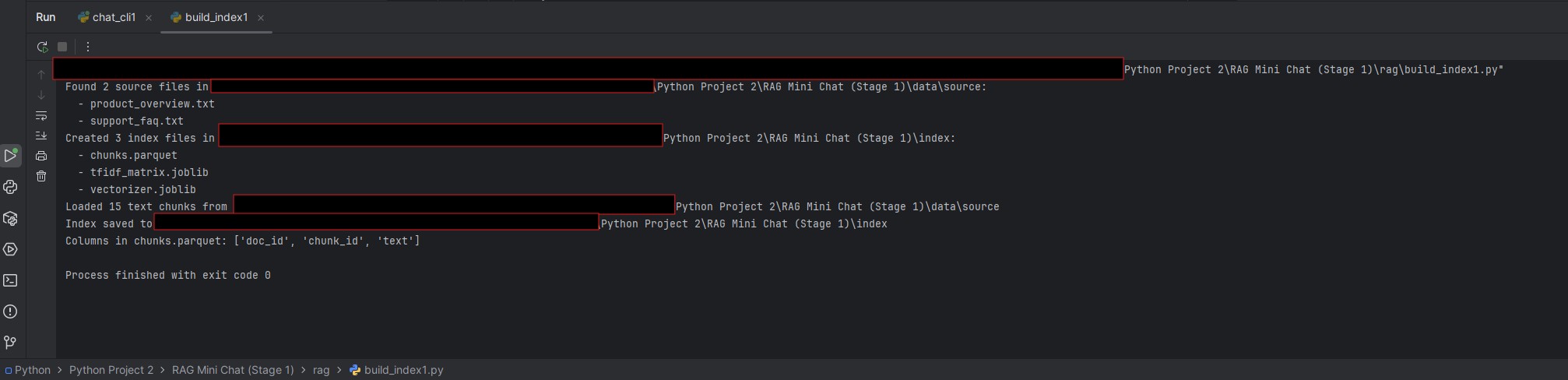
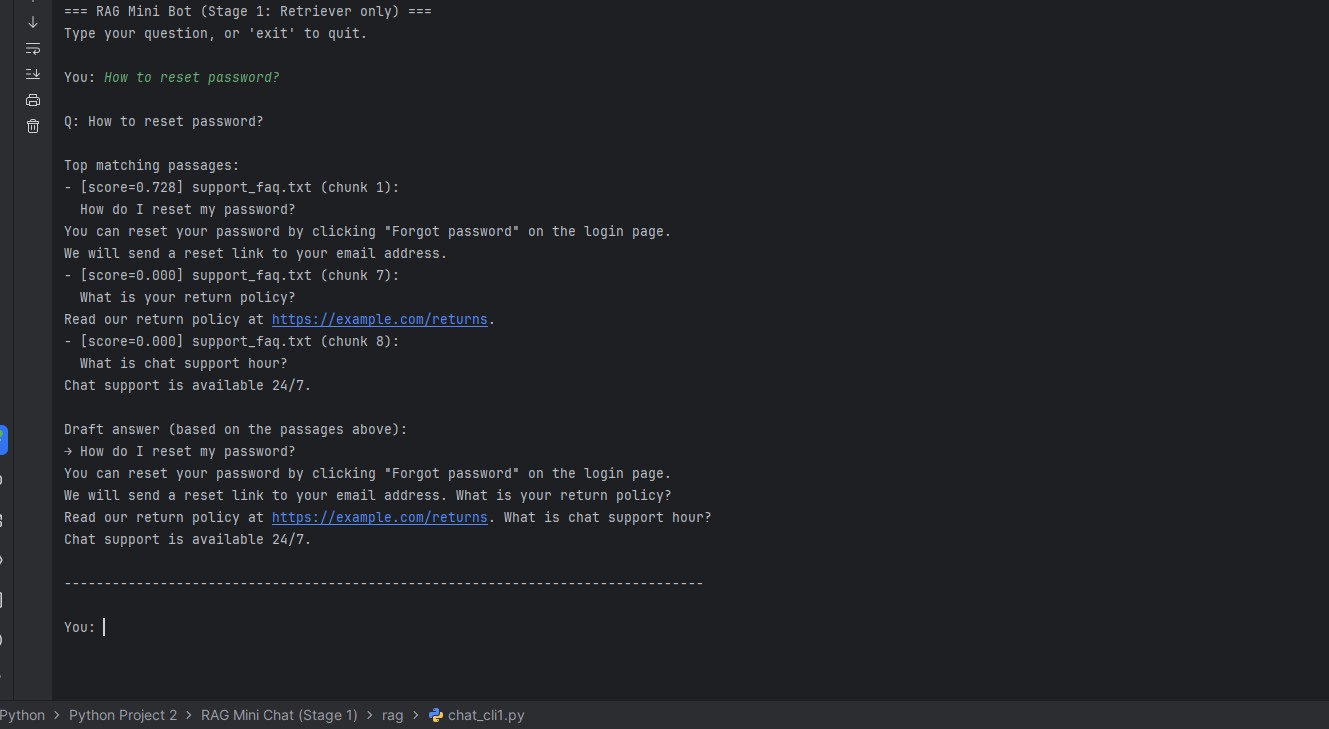
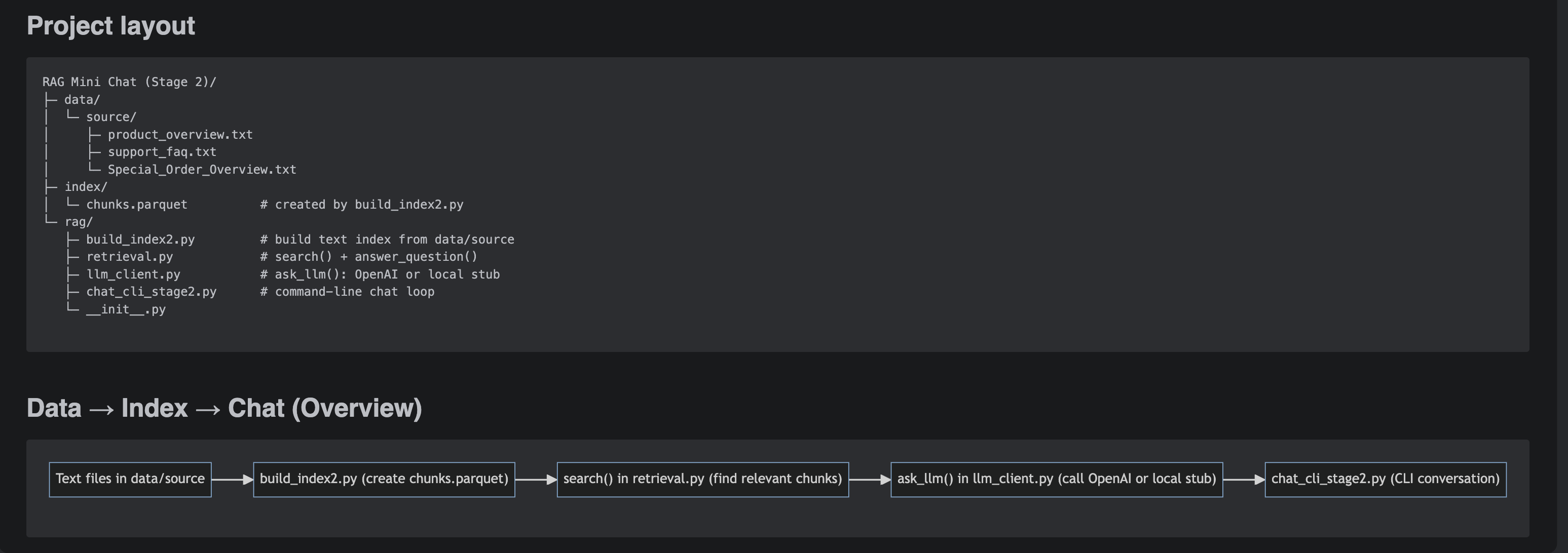
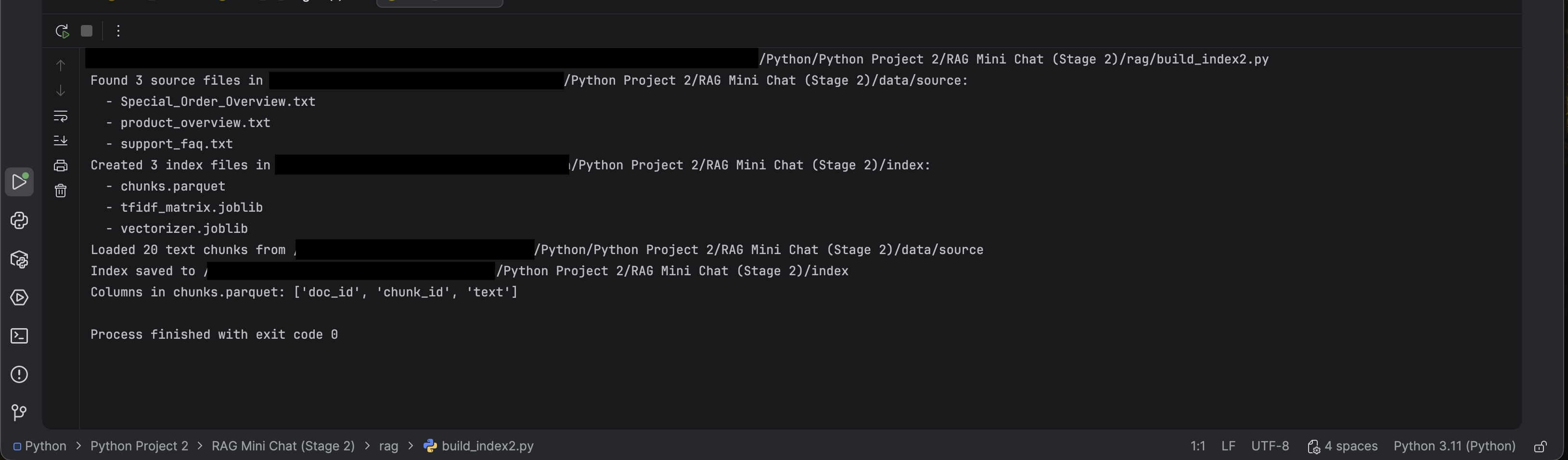
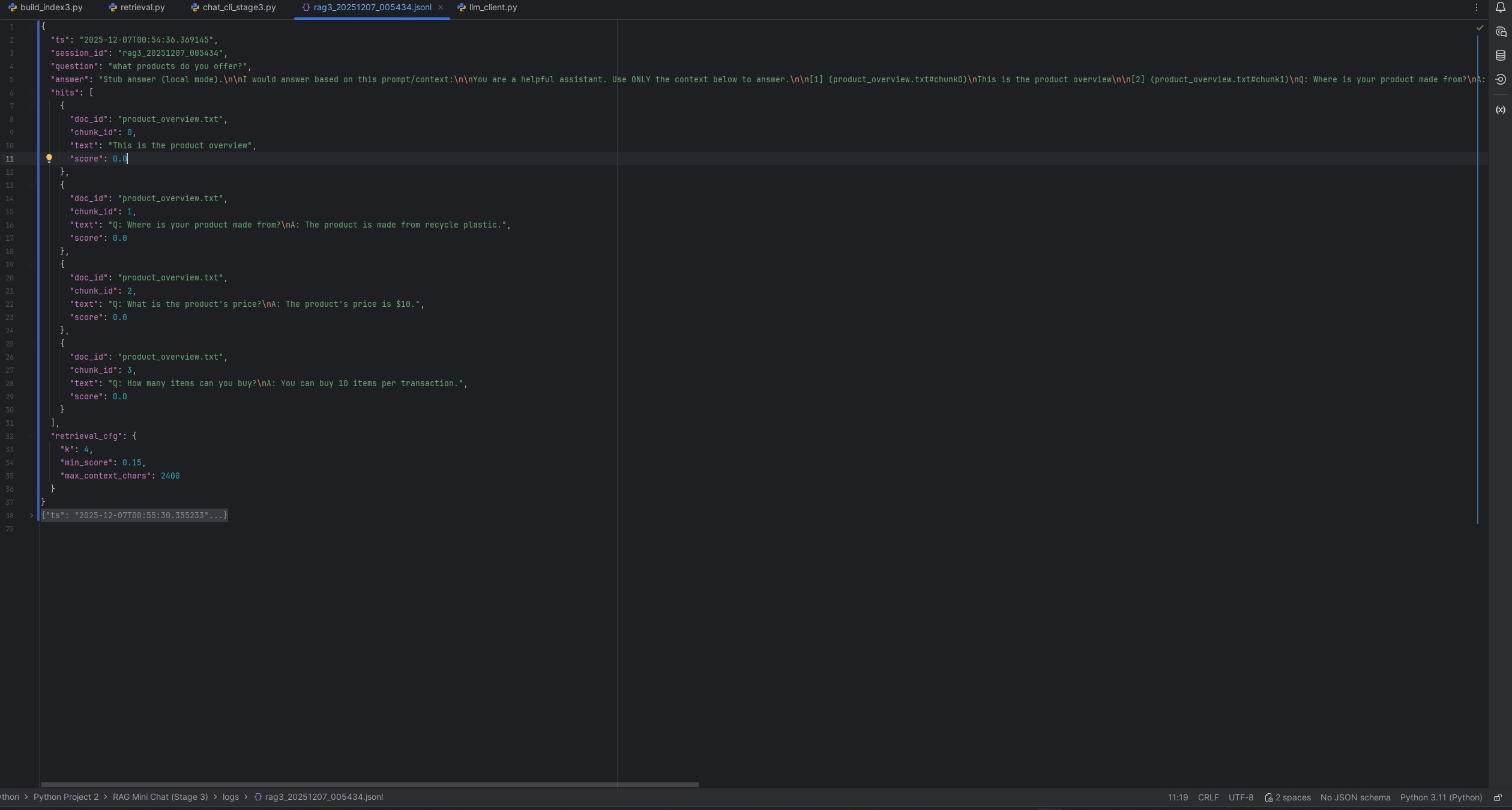
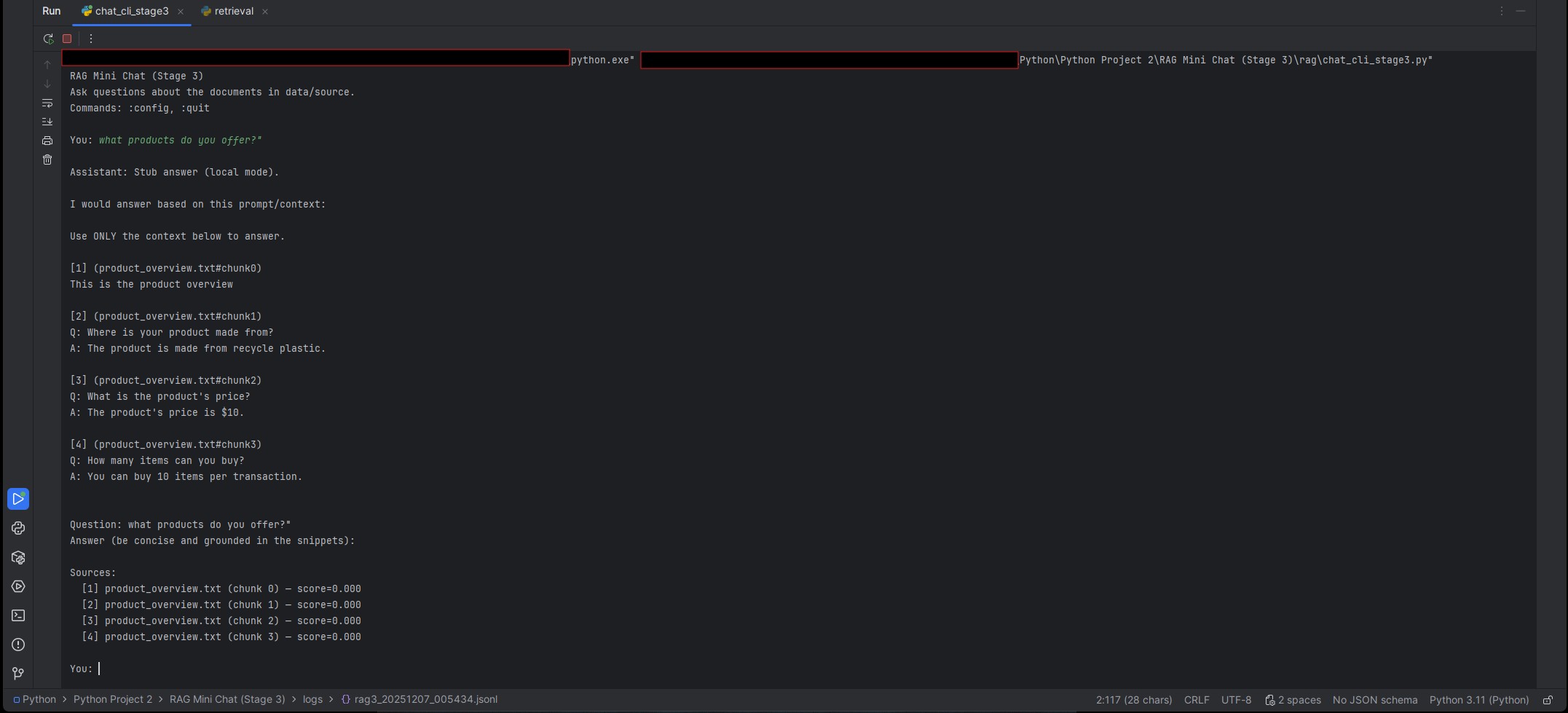
Staged RAG build (single-doc → multi-doc → logging) with grounding and run artifacts so answers are debuggable.
- Chunking + retrieval (top-k) with reviewable outputs.
- Grounded prompting to constrain answers to retrieved context.
- Run logs: question → retrieved chunks → final answer.
- Re-run flow:
python ingest.py→python chat.py(adjust to repo).
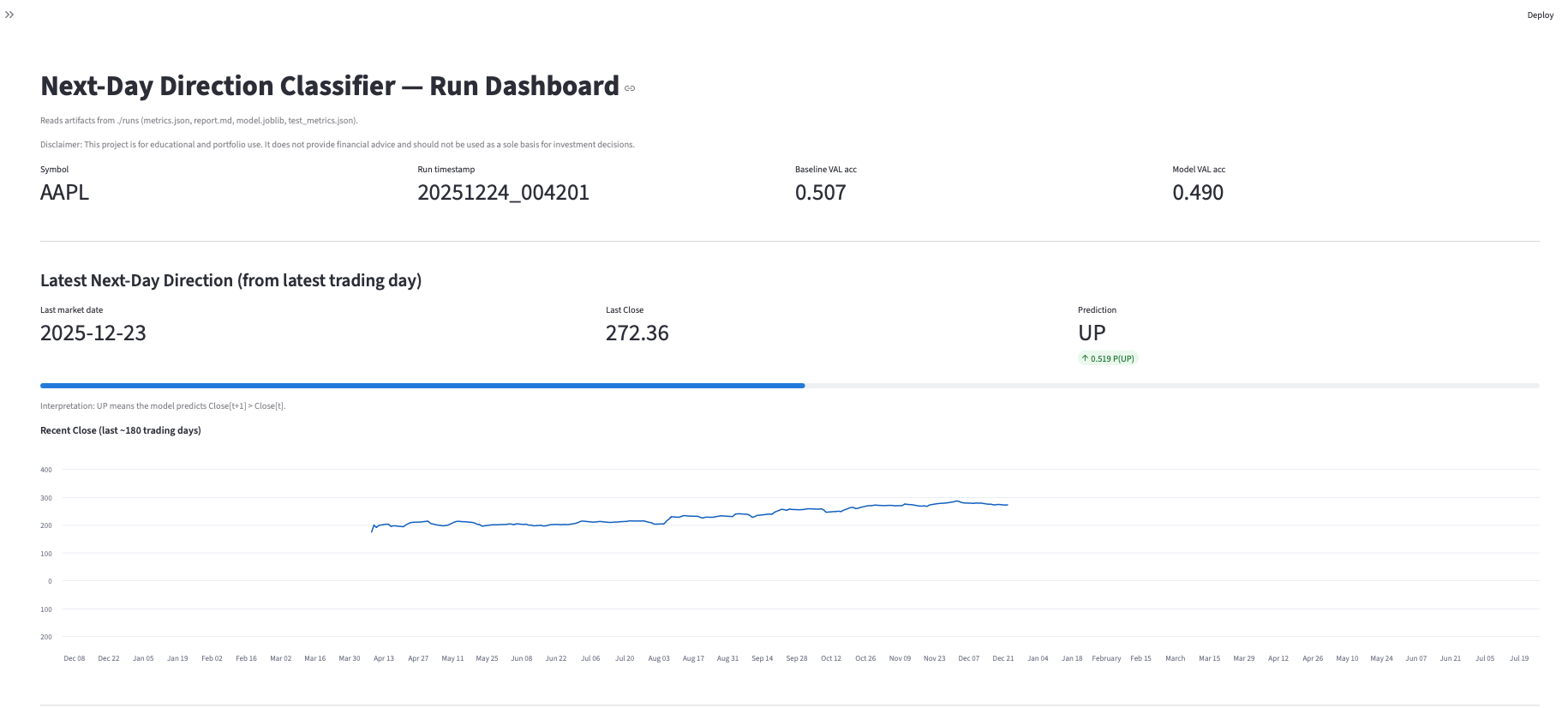
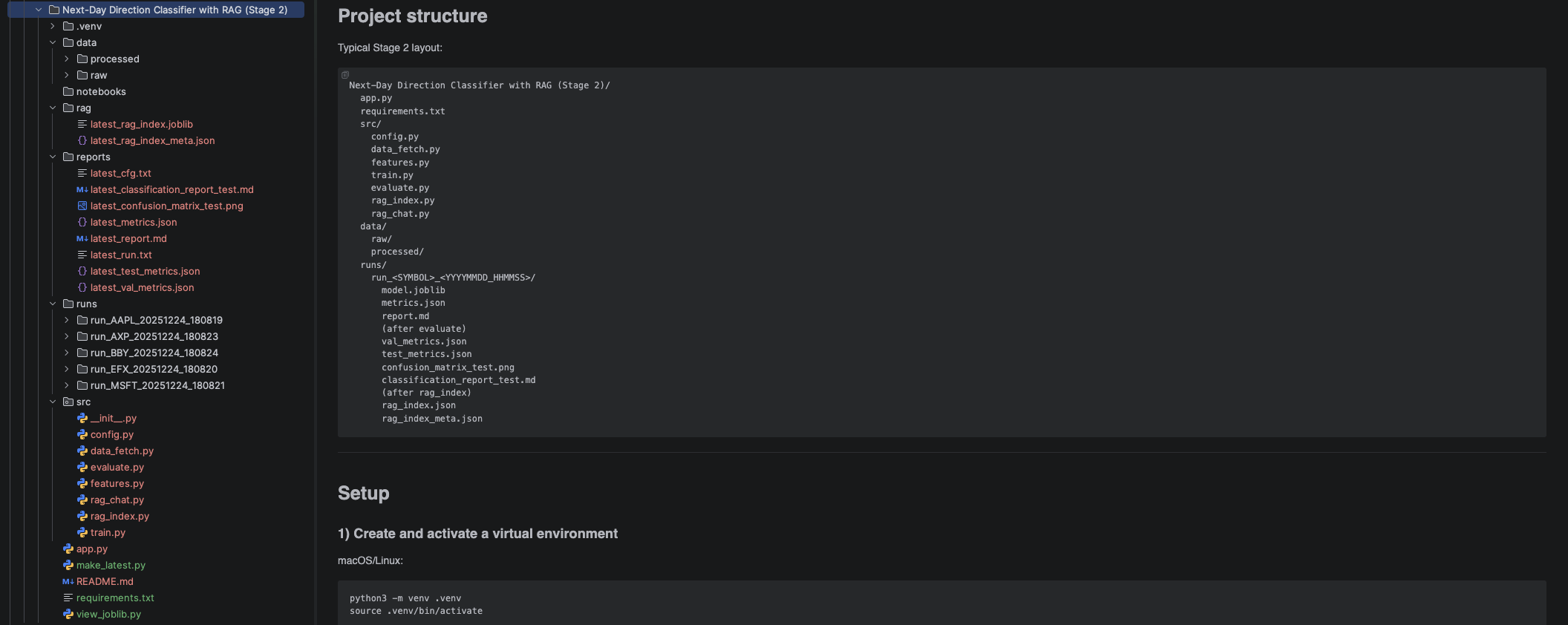
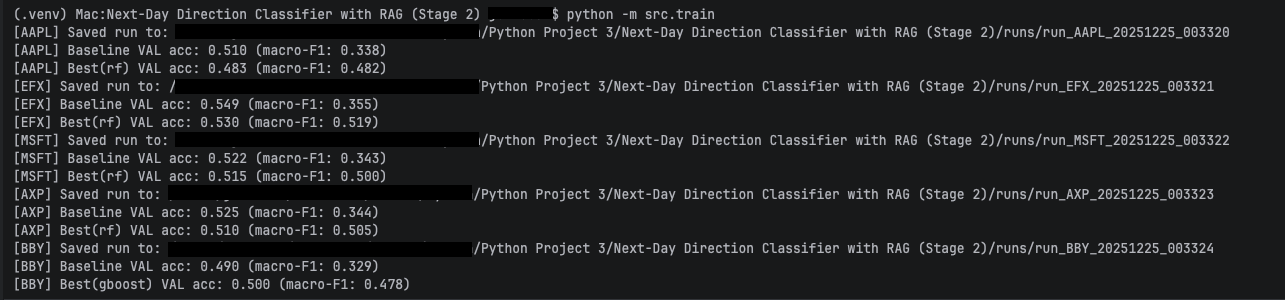
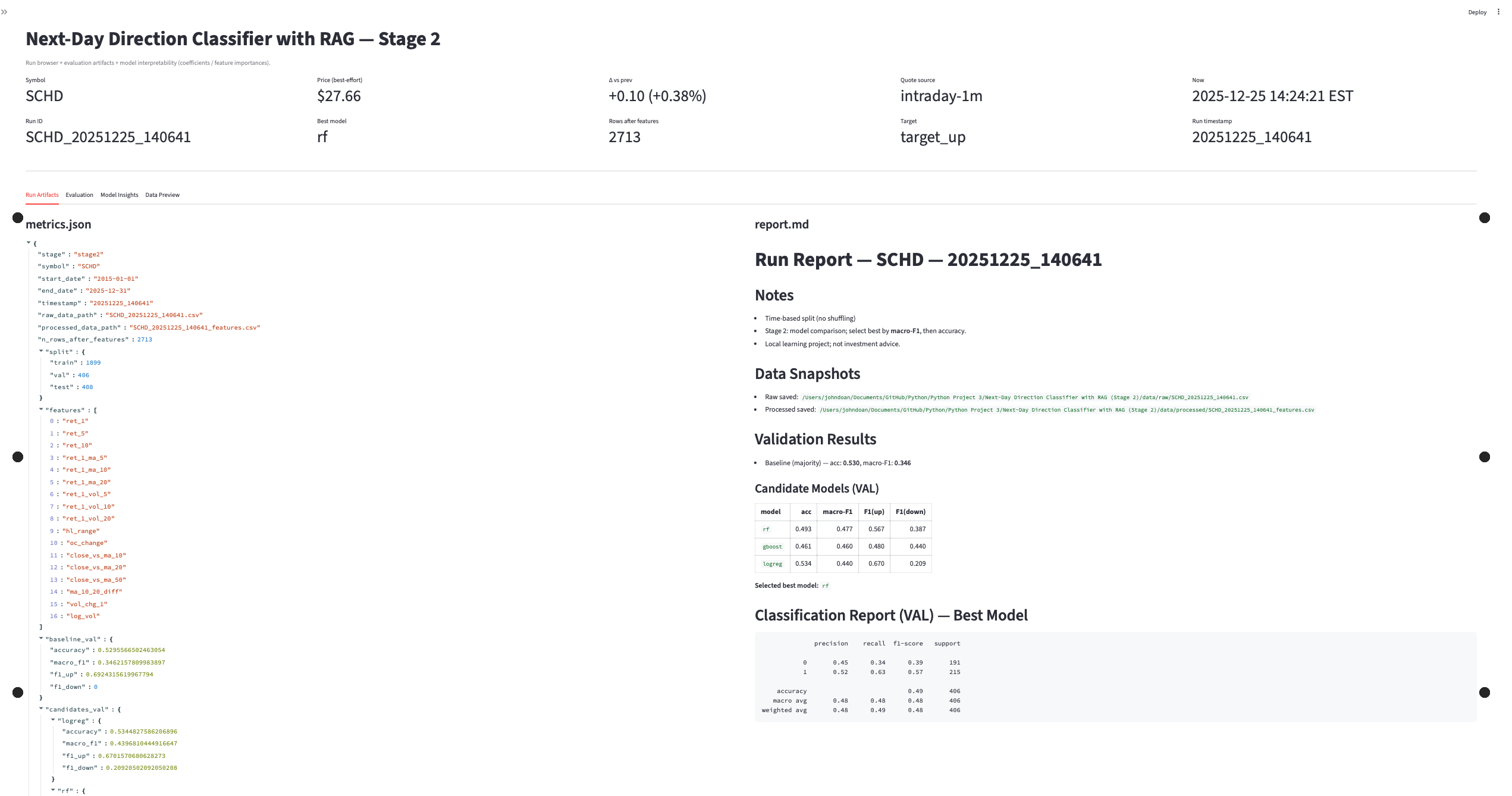
Next-Day Prediction Classifier with RAG
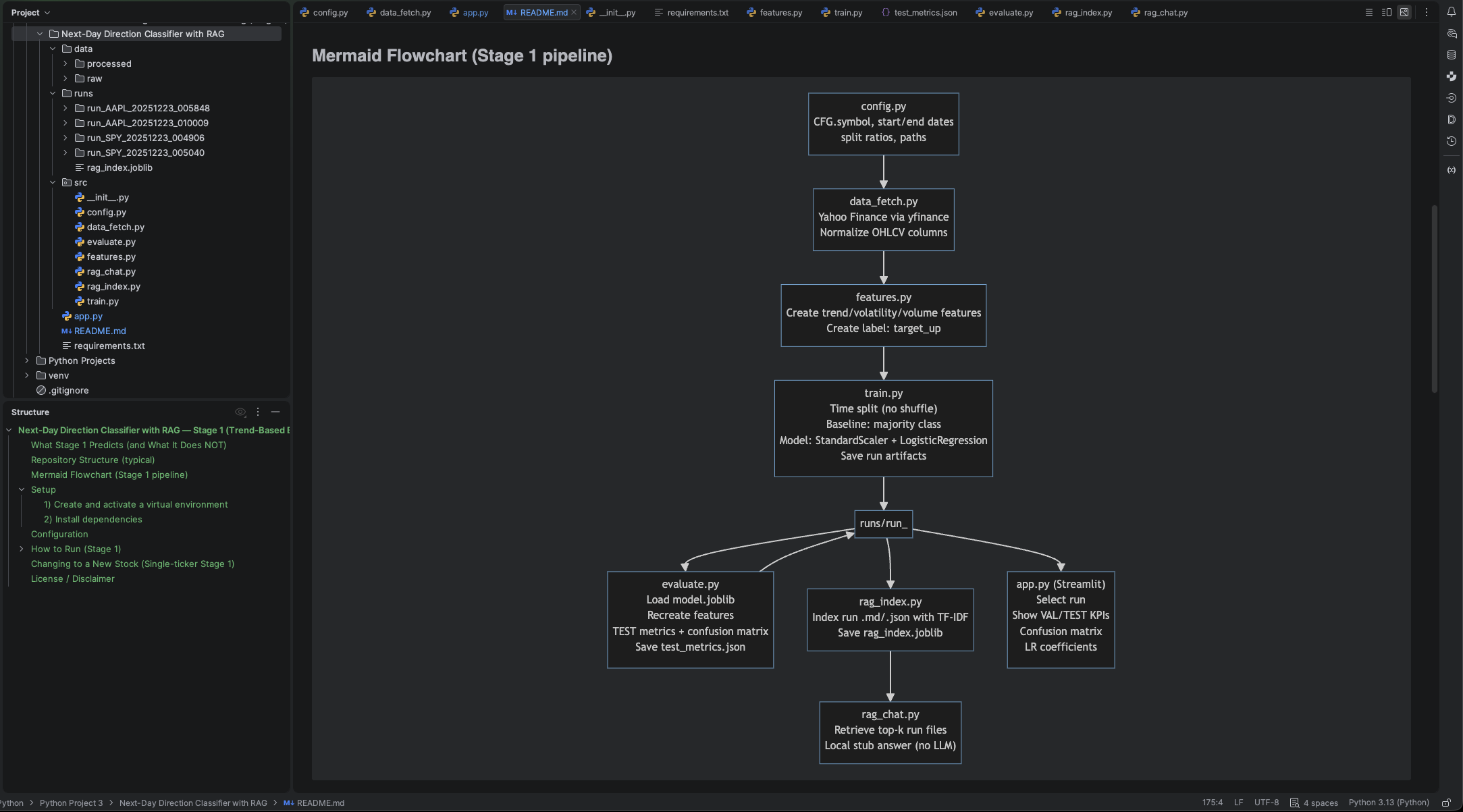
Direction classifier that augments features with retrieved context and logs training/evaluation outputs for traceability and debugging.
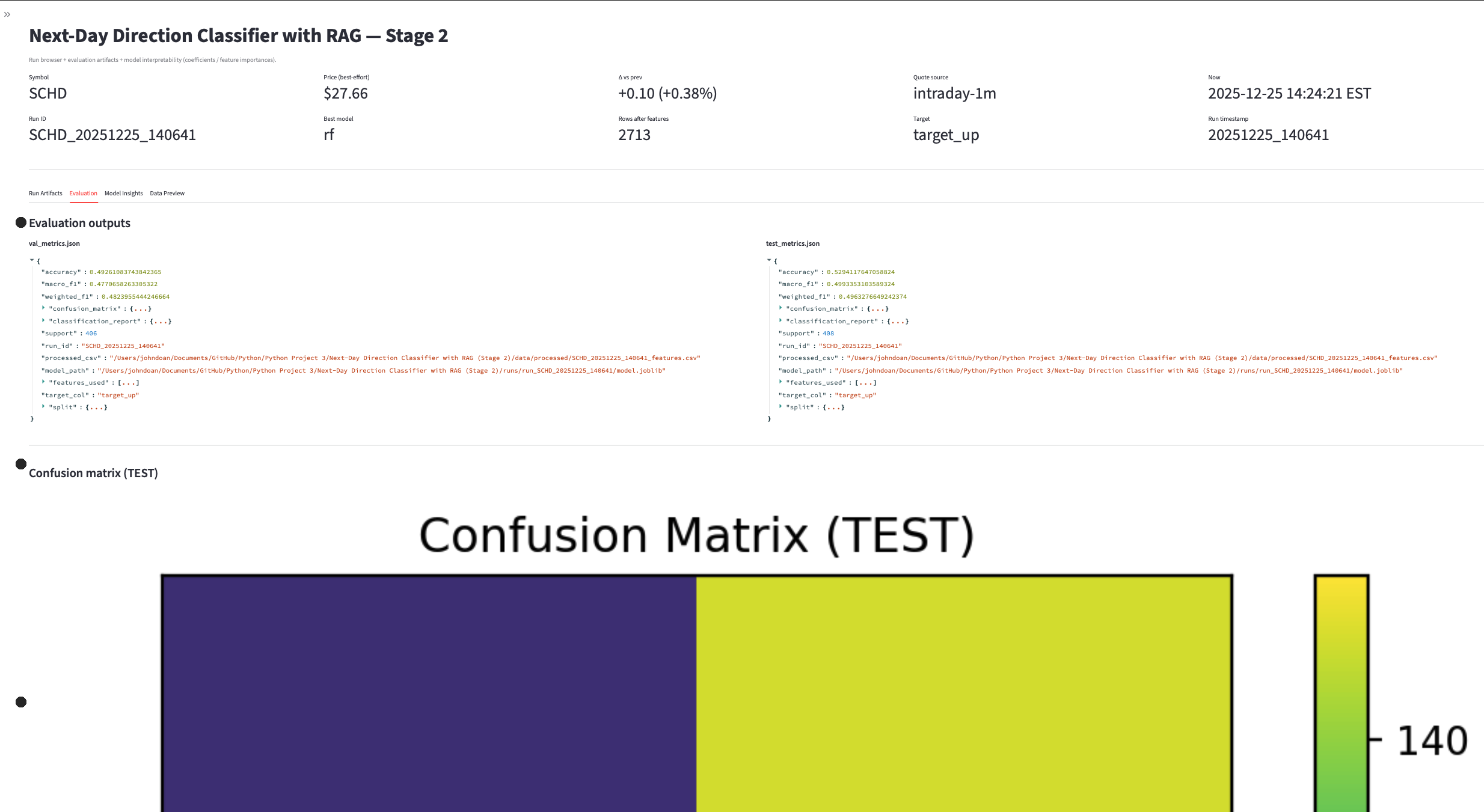
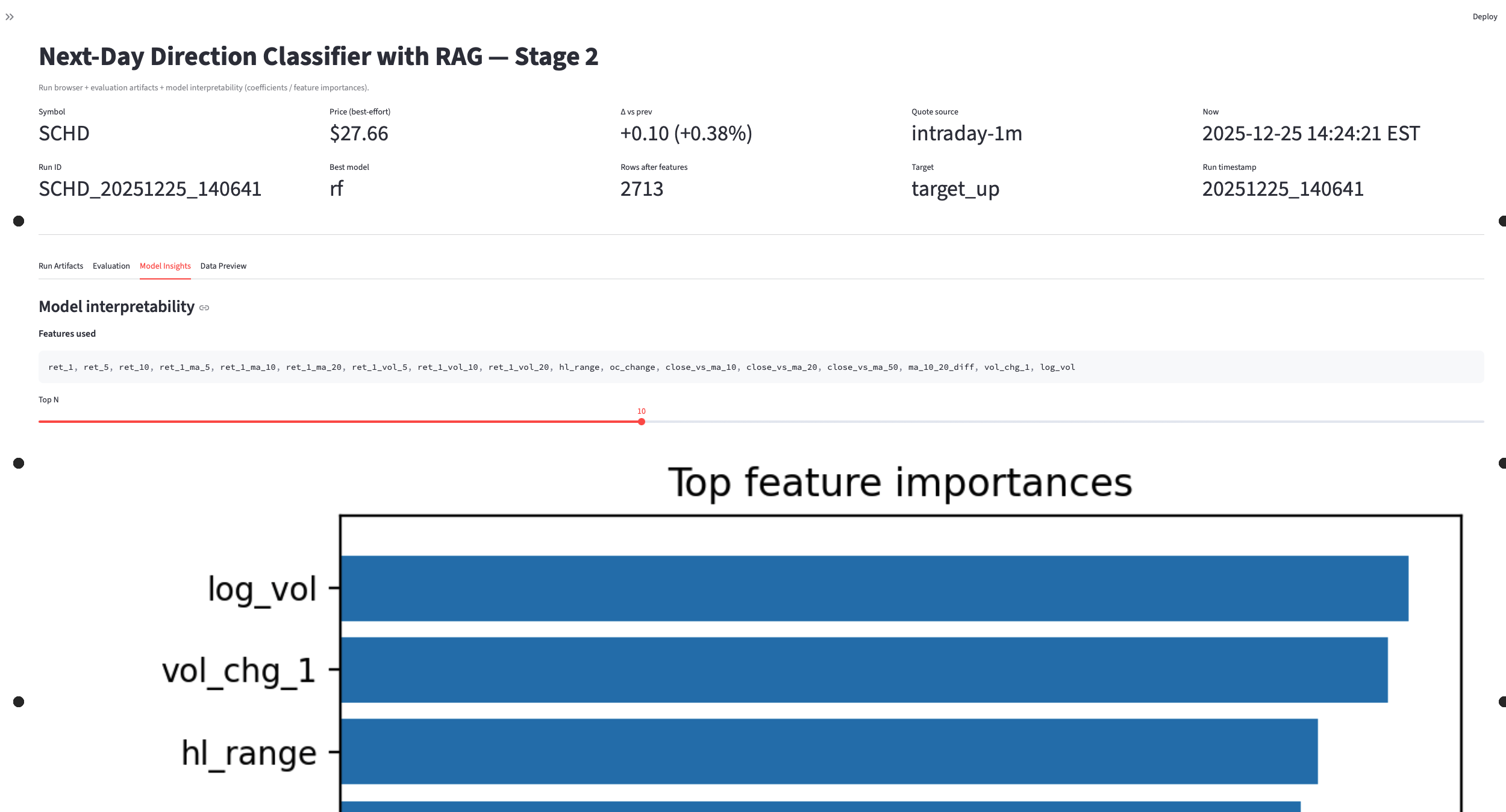
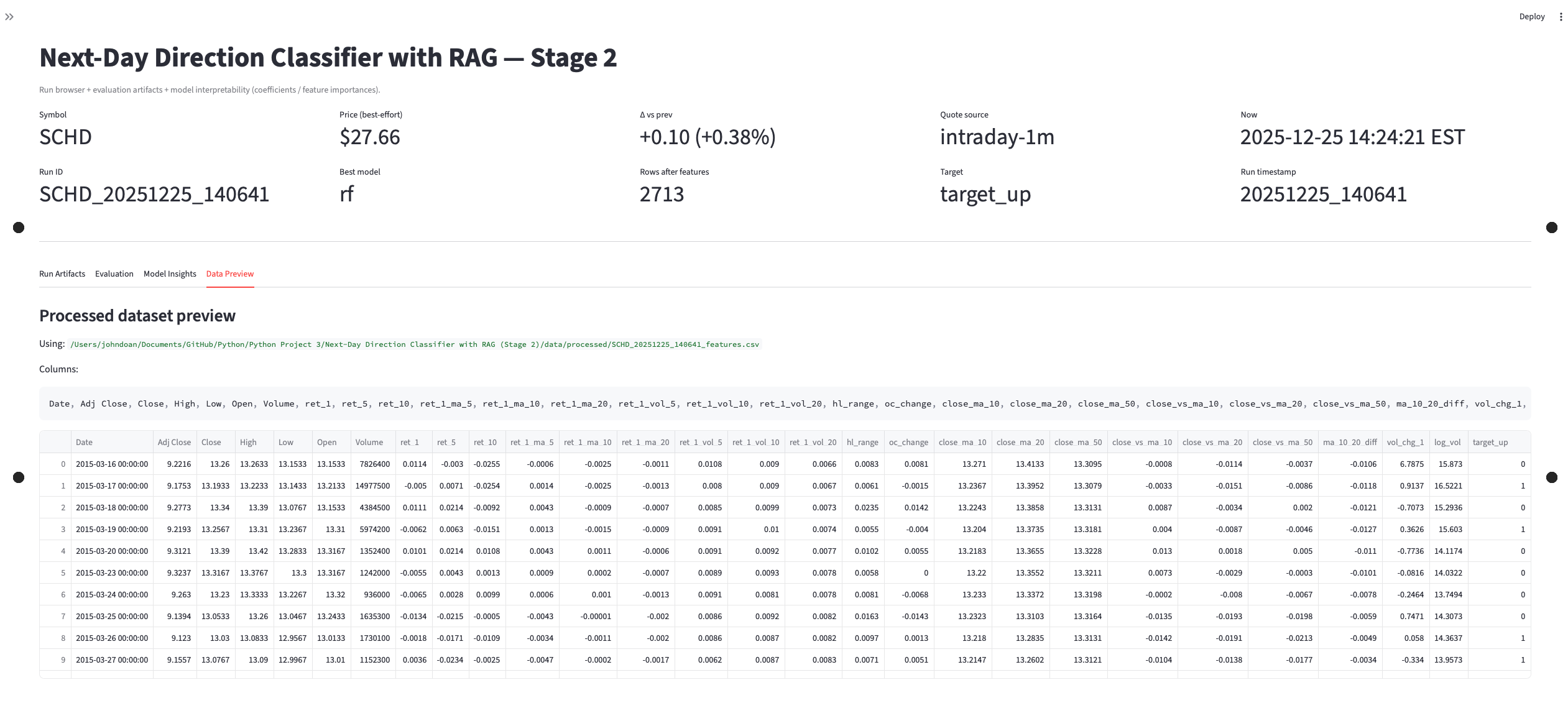
- Classifier trained and evaluated with saved outputs for review.
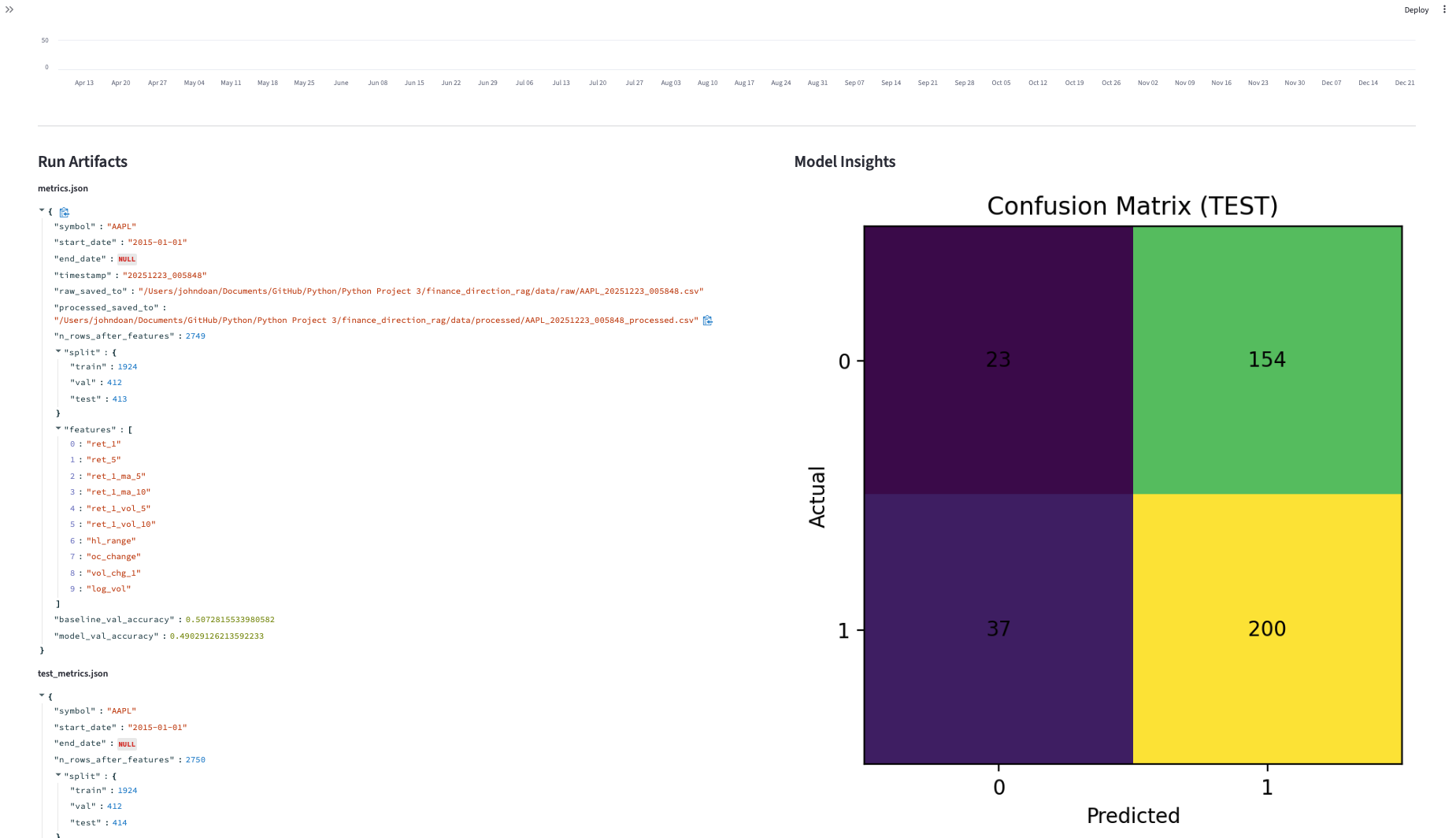
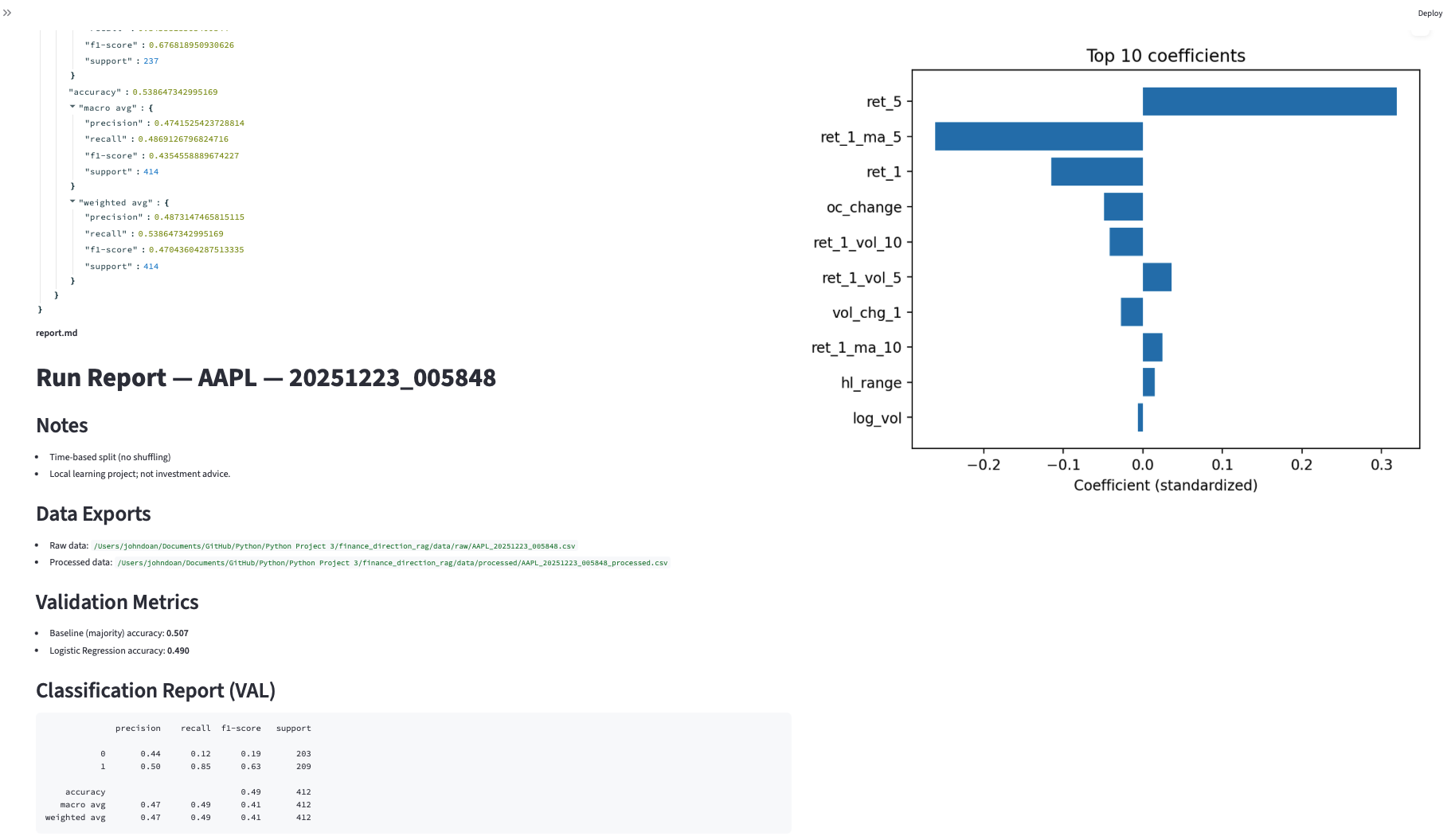
- Artifacts: training output, evaluation report, confusion matrix, and model insight views.
- Re-run flow:
python train.py→python eval.py(adjust to repo).
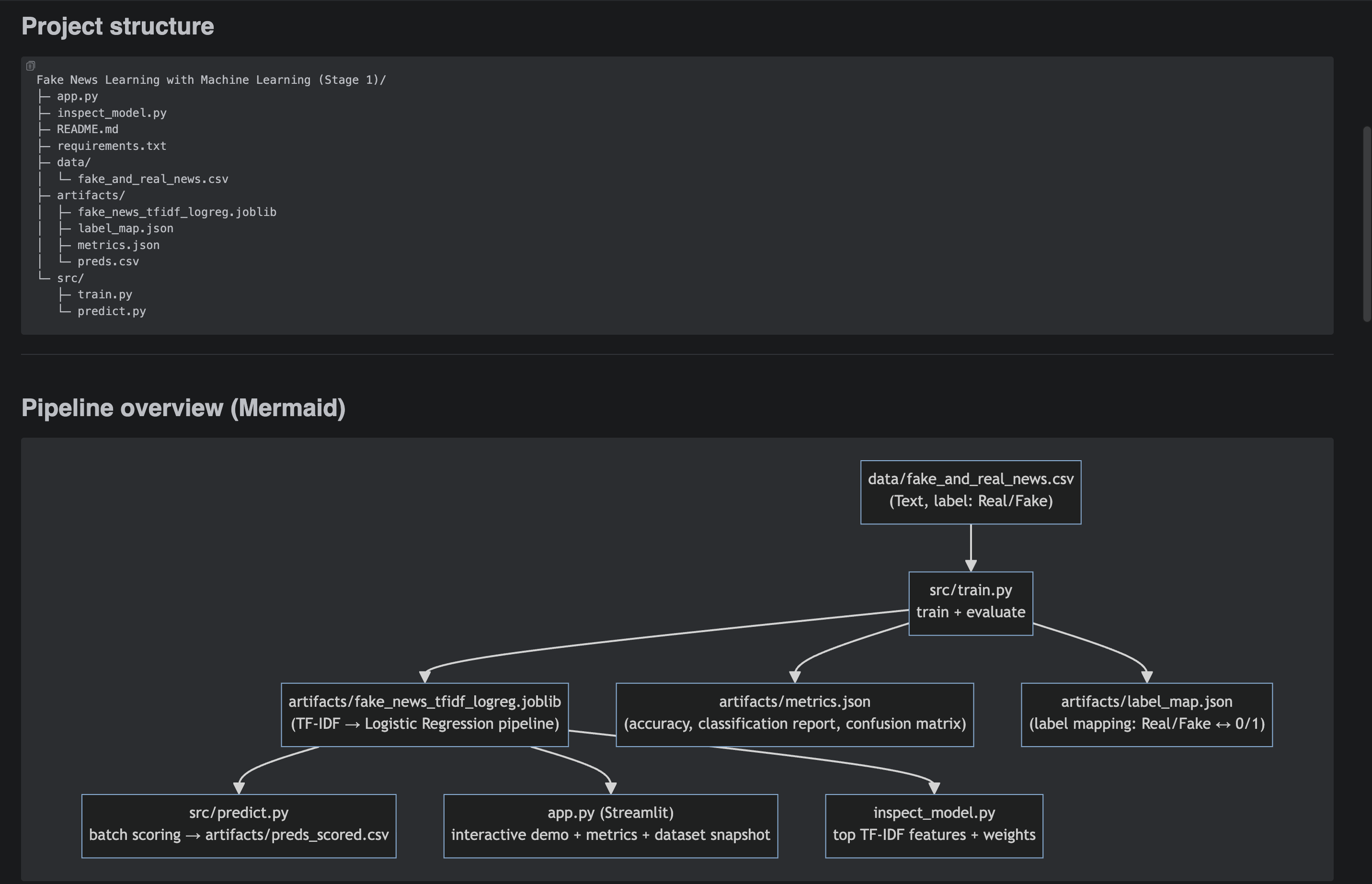
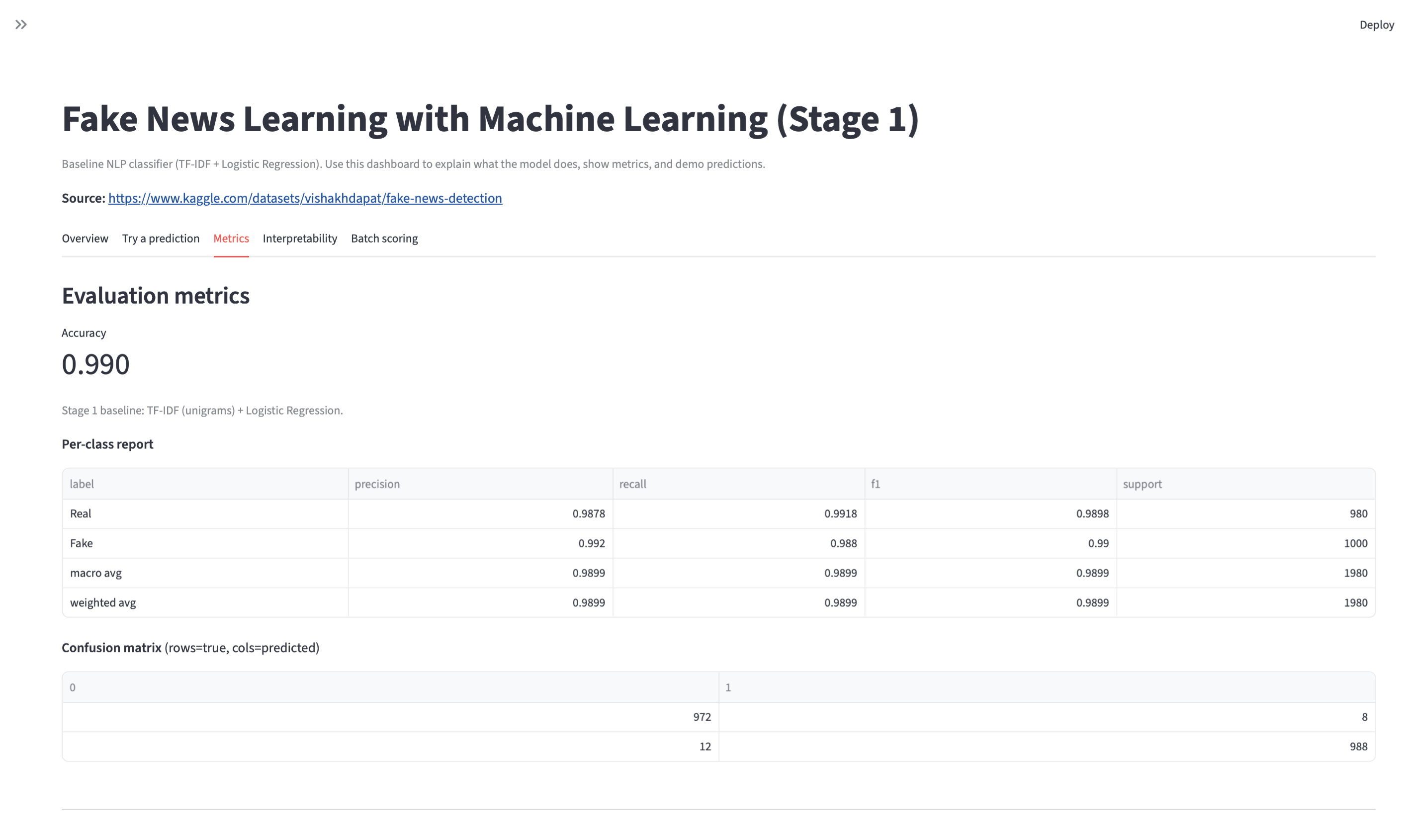
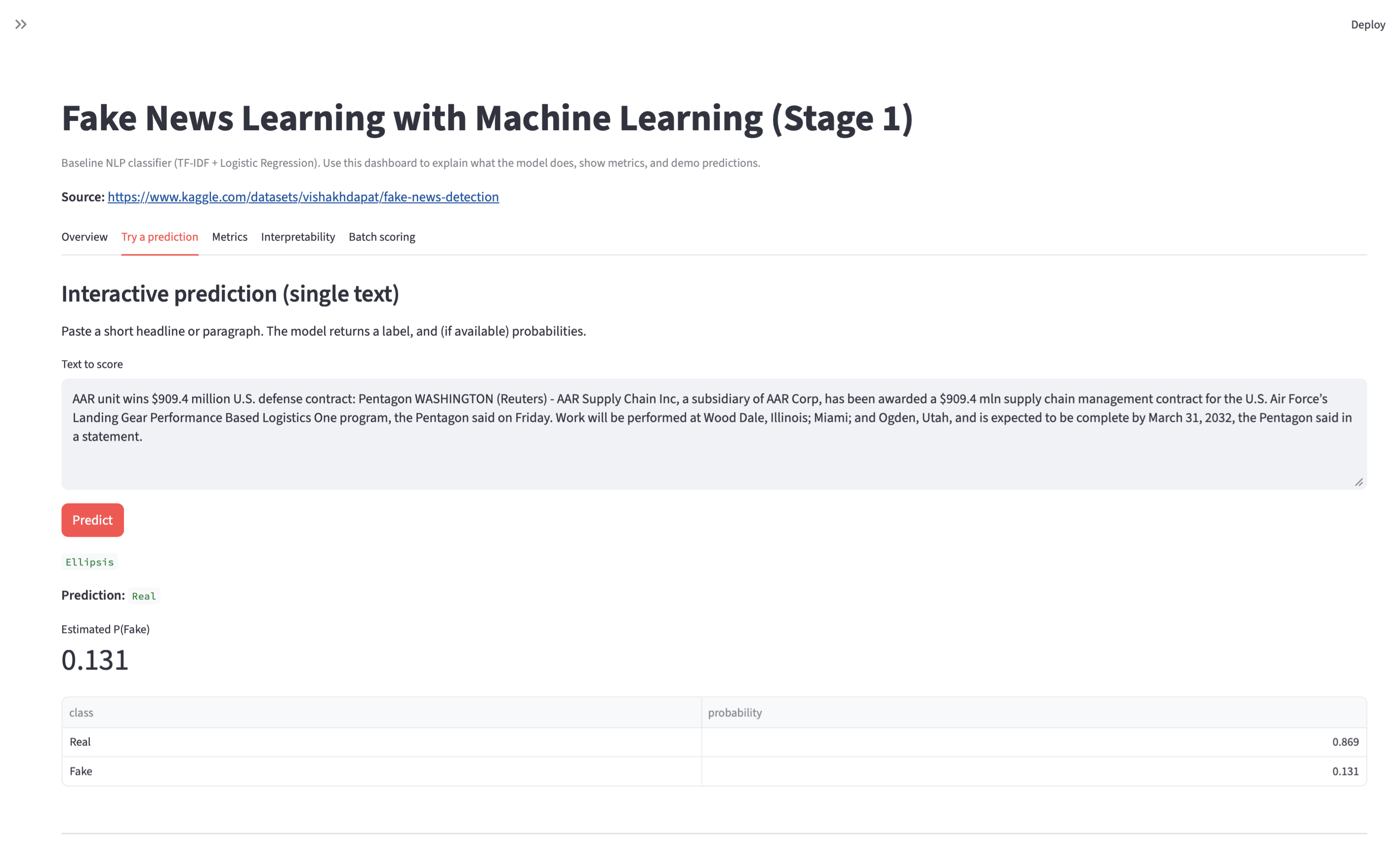
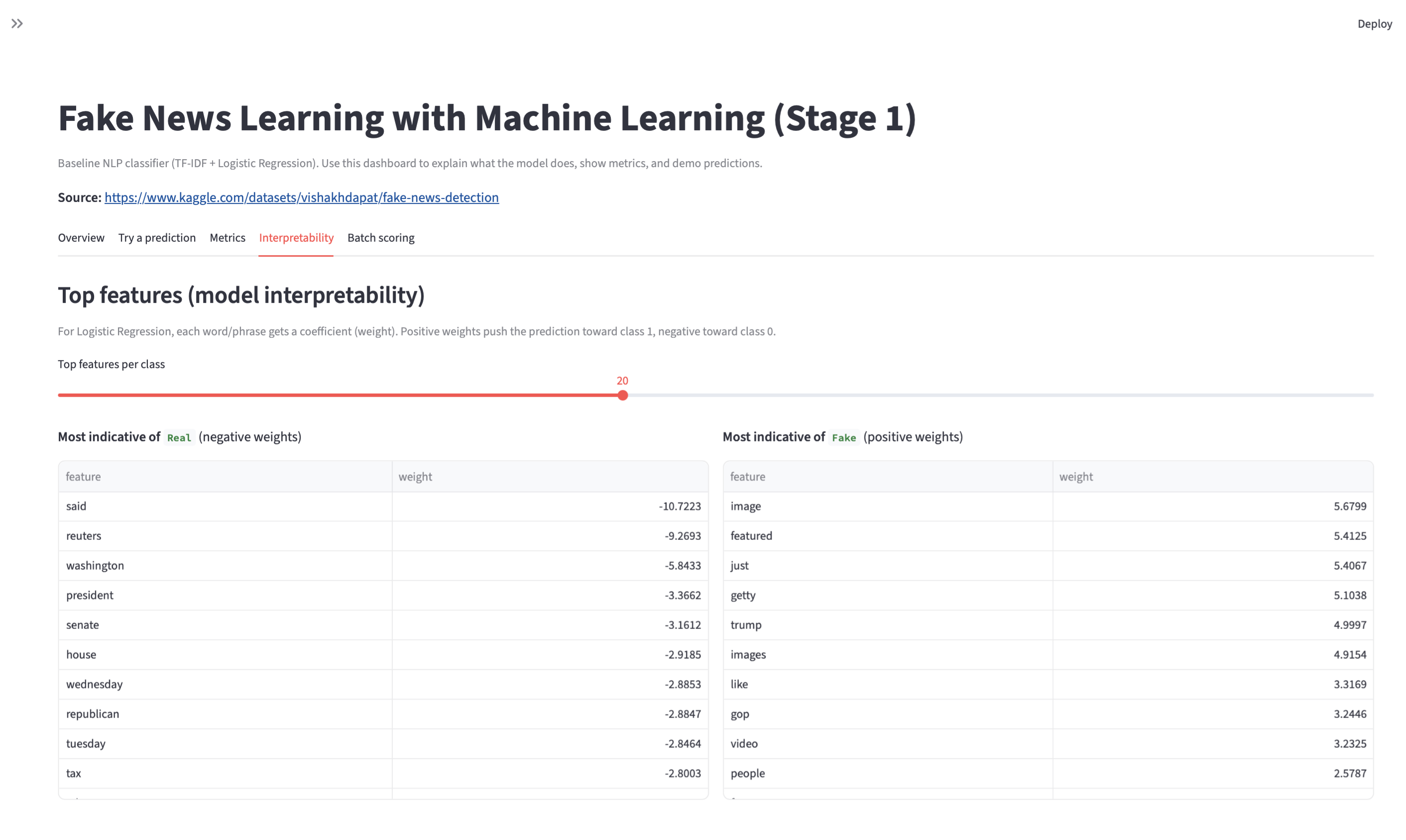
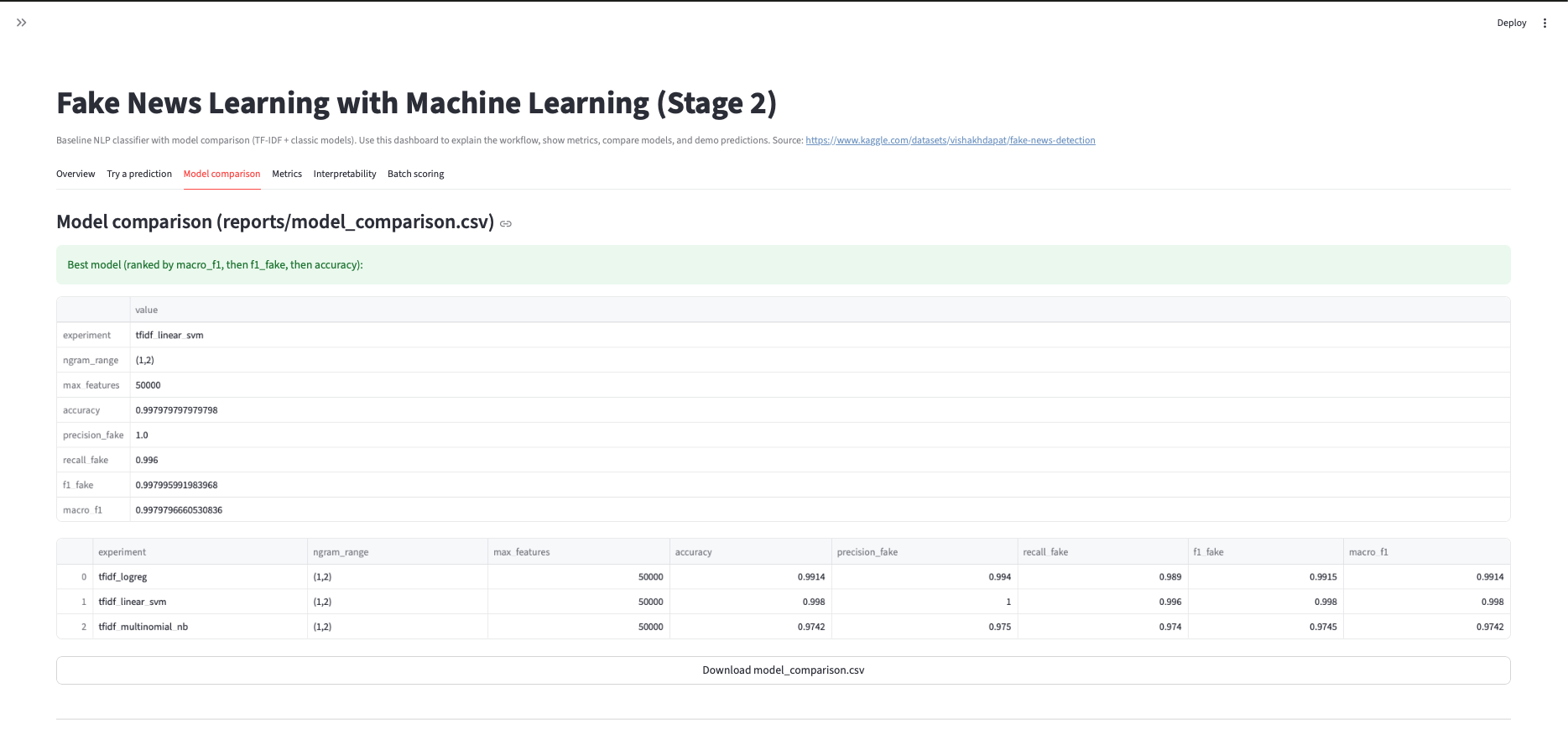
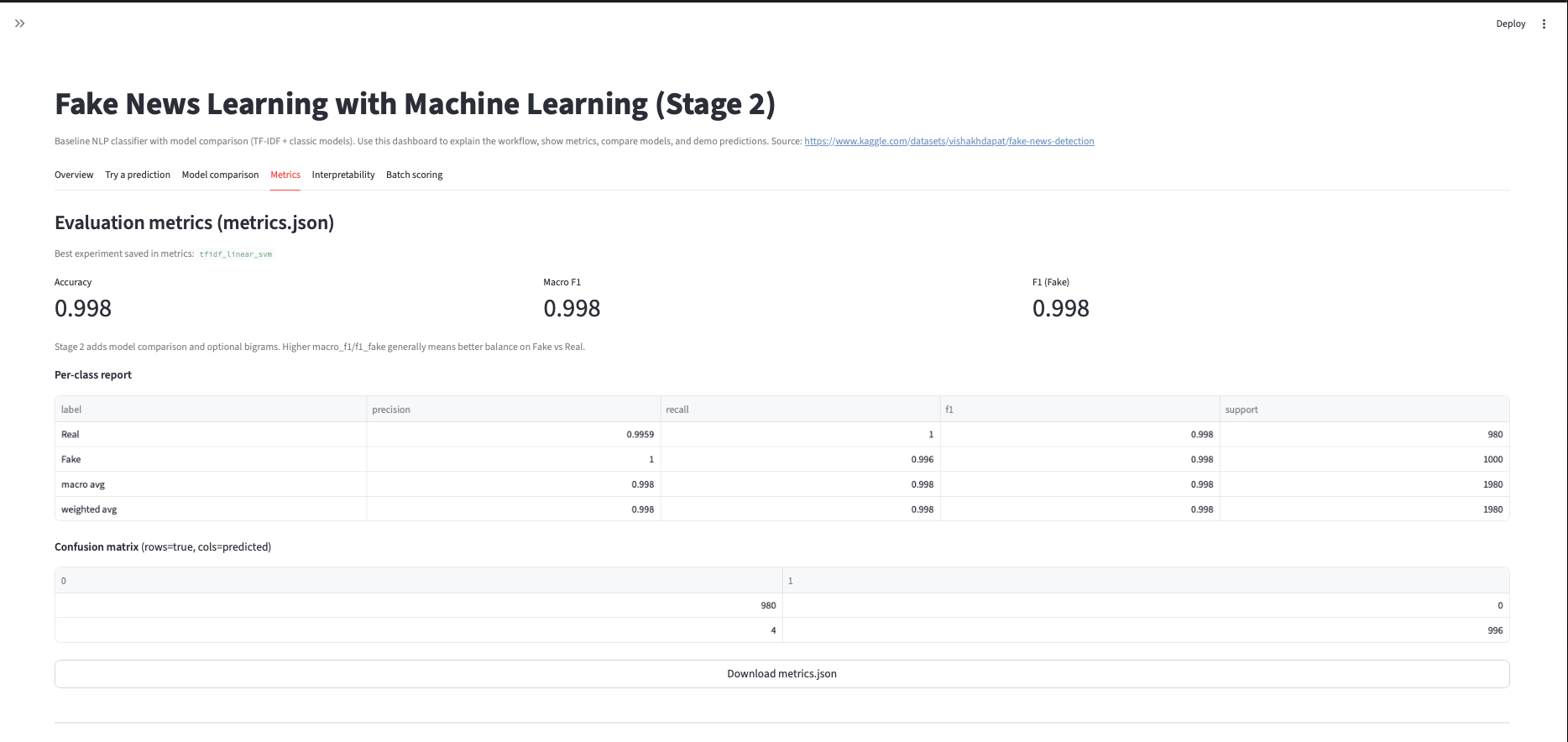
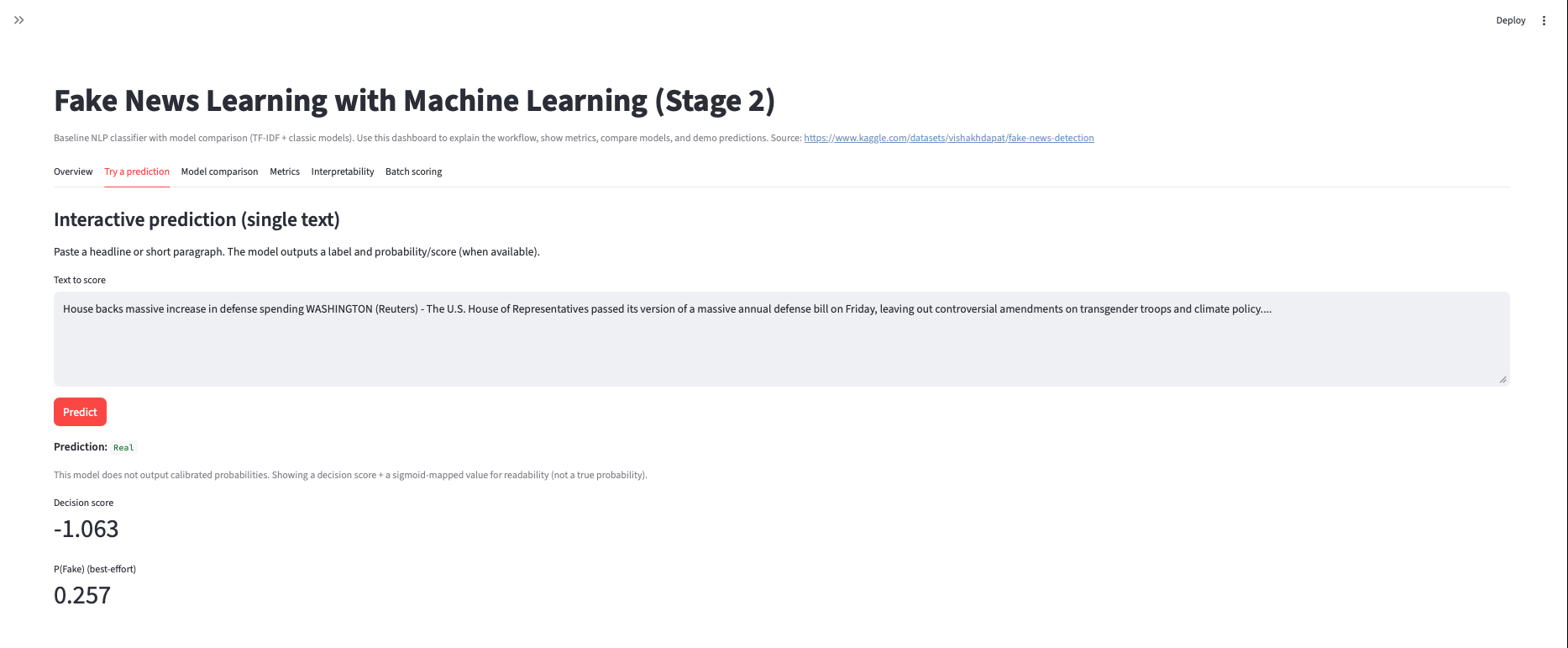
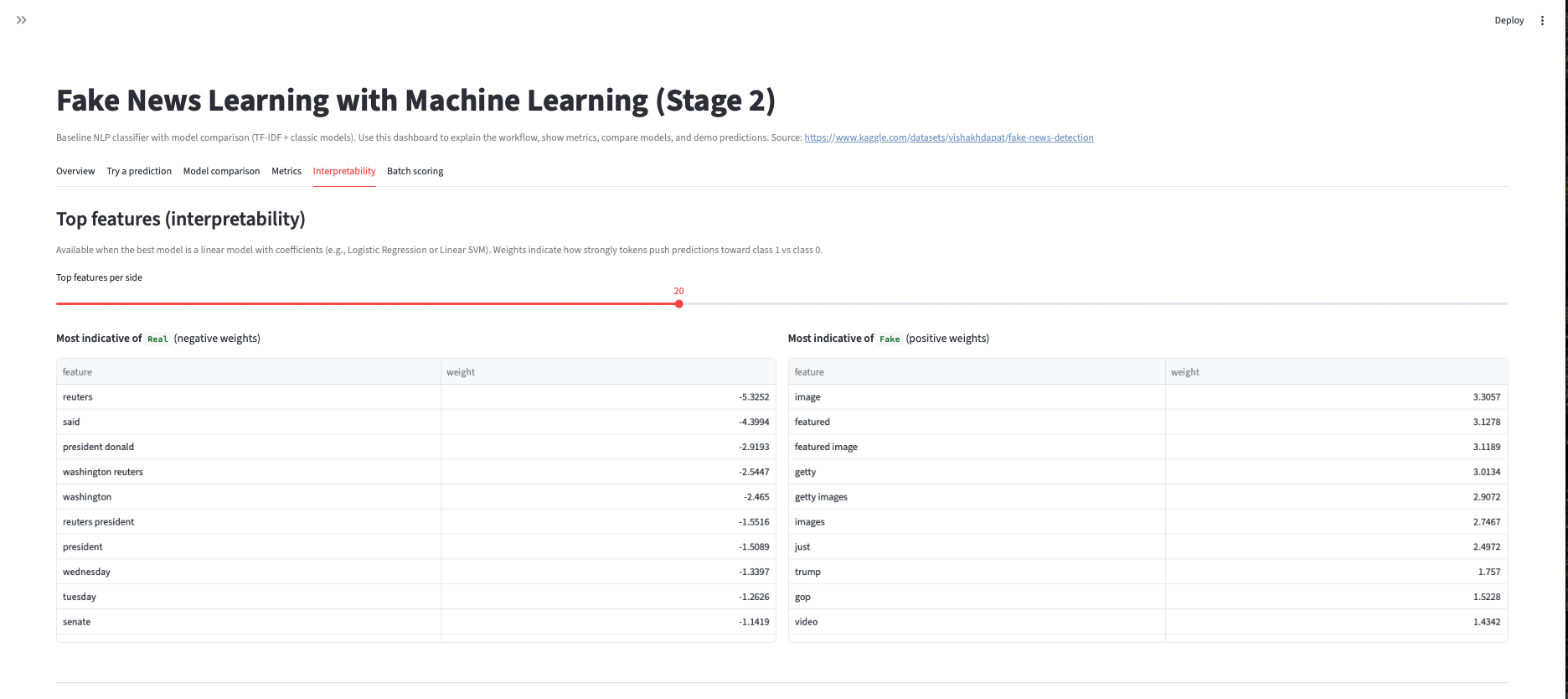
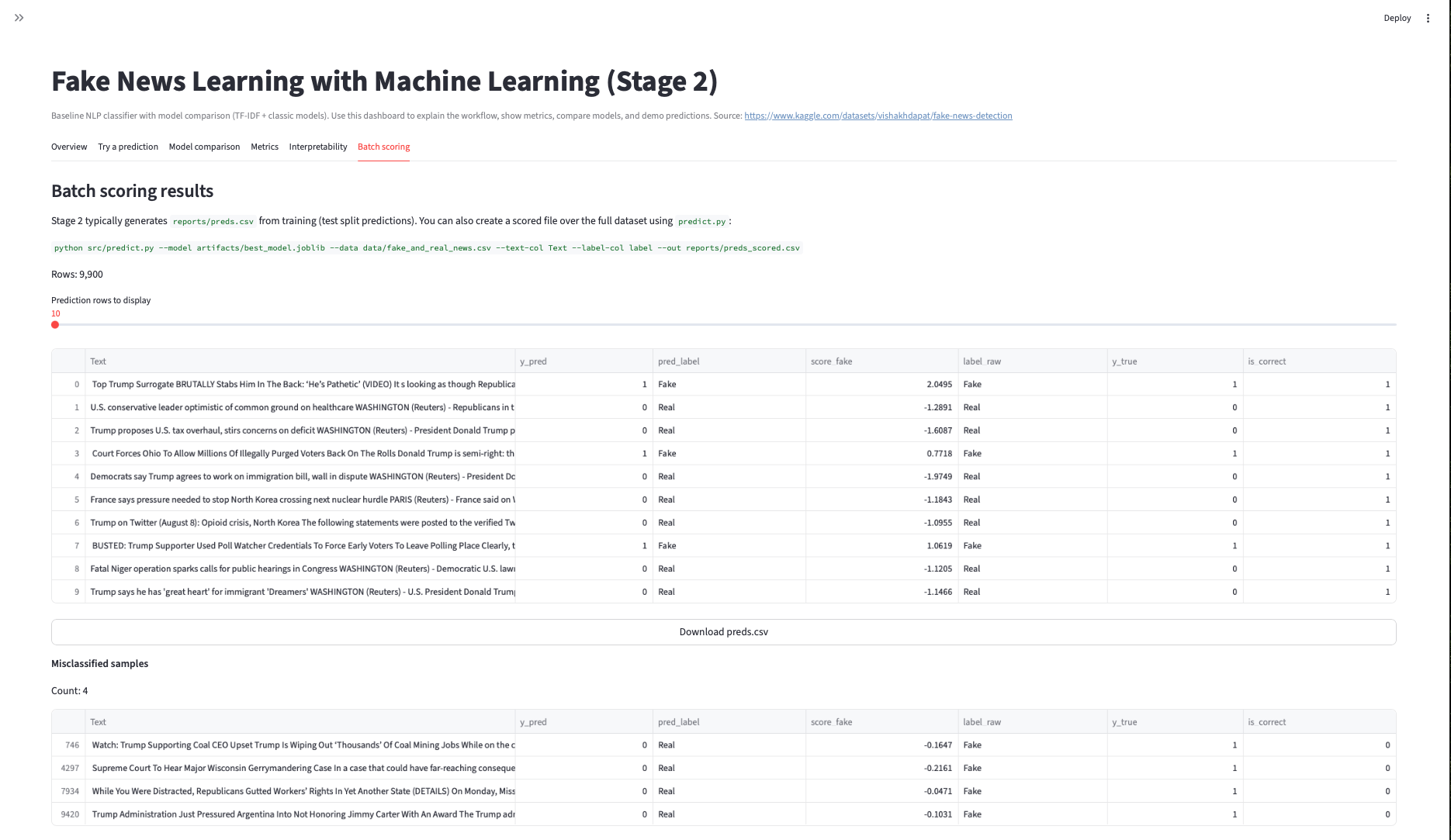
Fake News Learning with ML
Three-stage NLP build: baseline pipeline → improved modeling → final evaluation and error review, with saved artifacts and reproducible runs. Models are trained on the Kaggle Fake News Detection dataset.
- Dataset: Kaggle — Fake News Detection.
- Stage 1: text cleaning + TF-IDF + baseline classifier.
- Stage 2: tuning/iterations (n-grams, regularization, model comparisons).
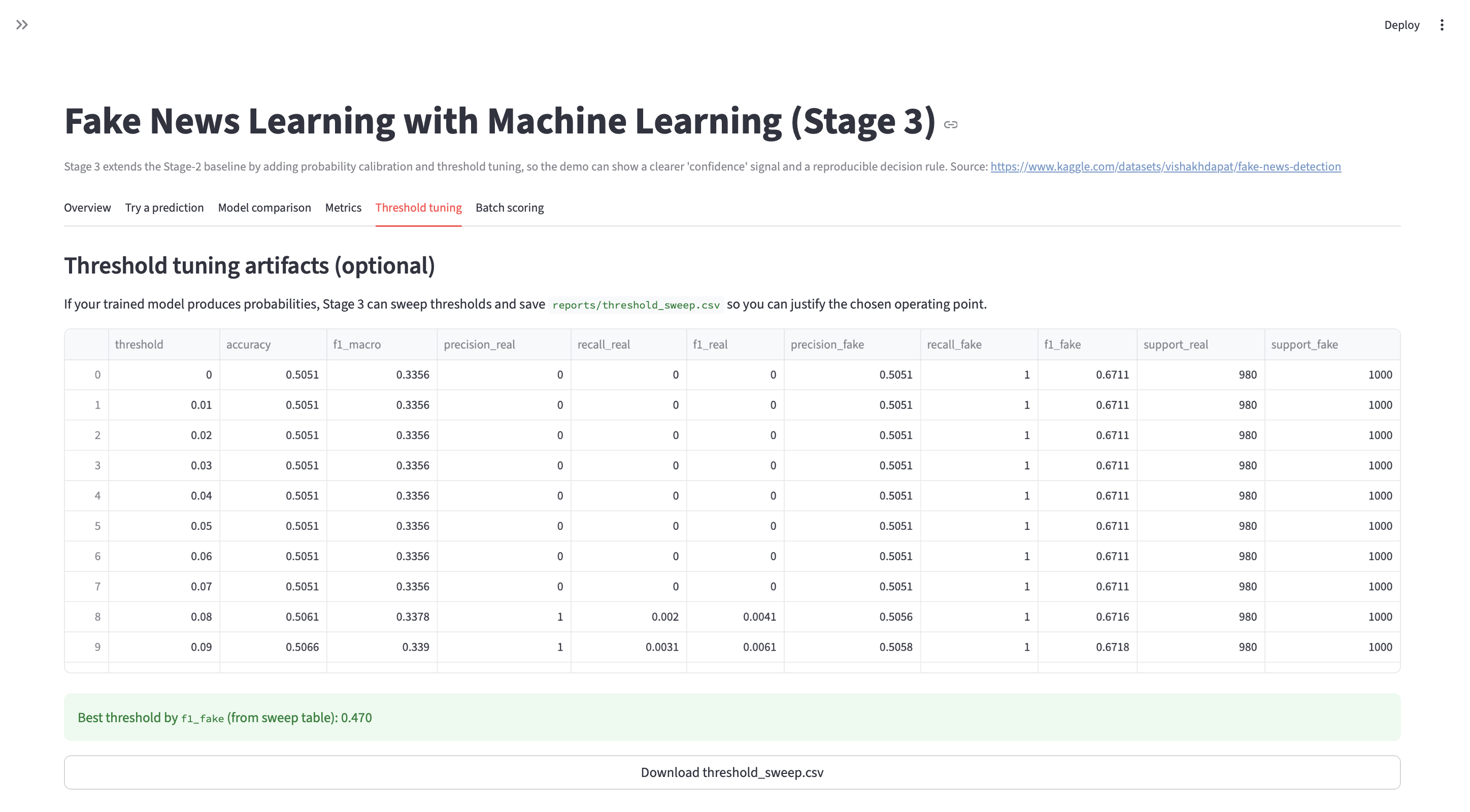
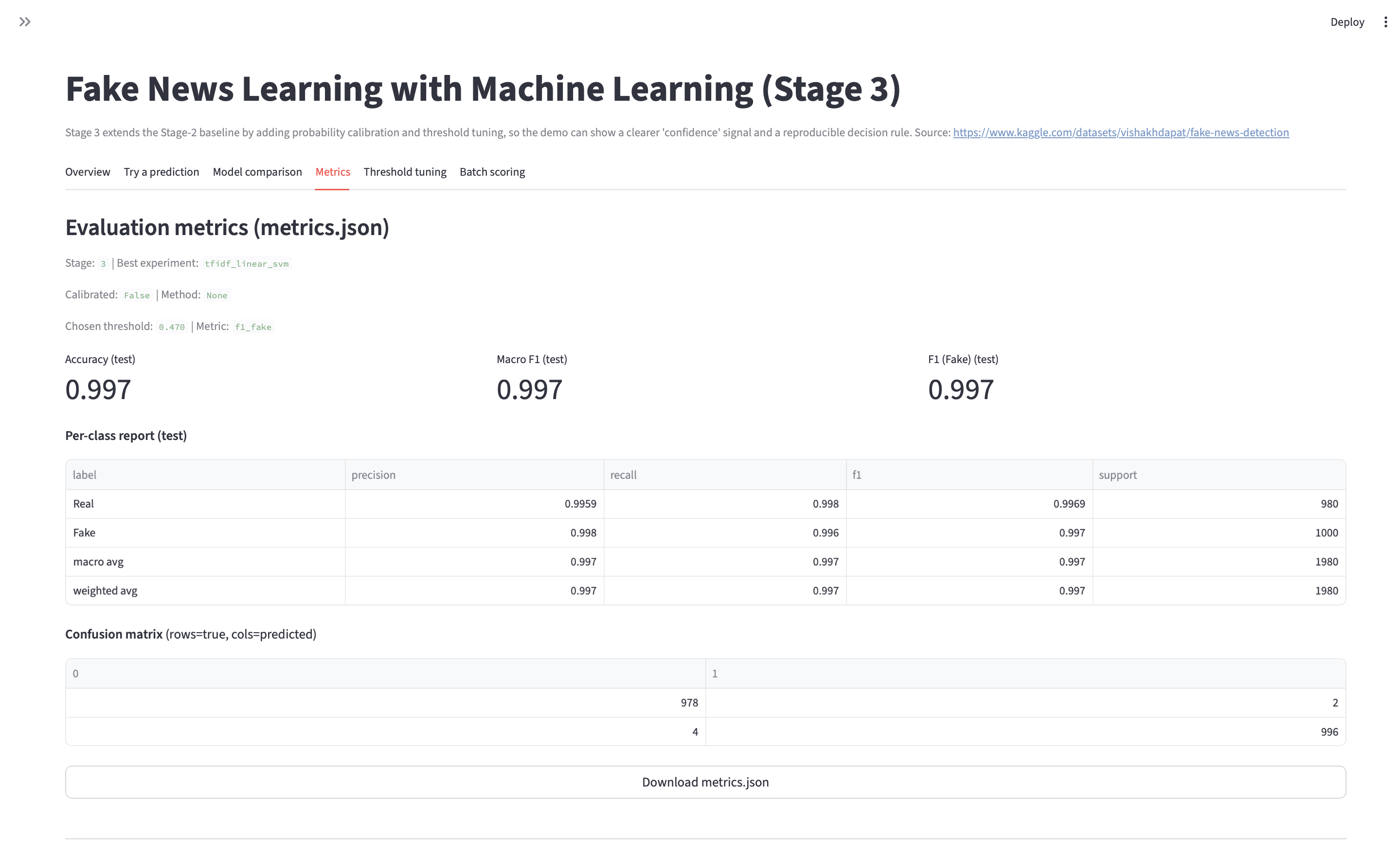
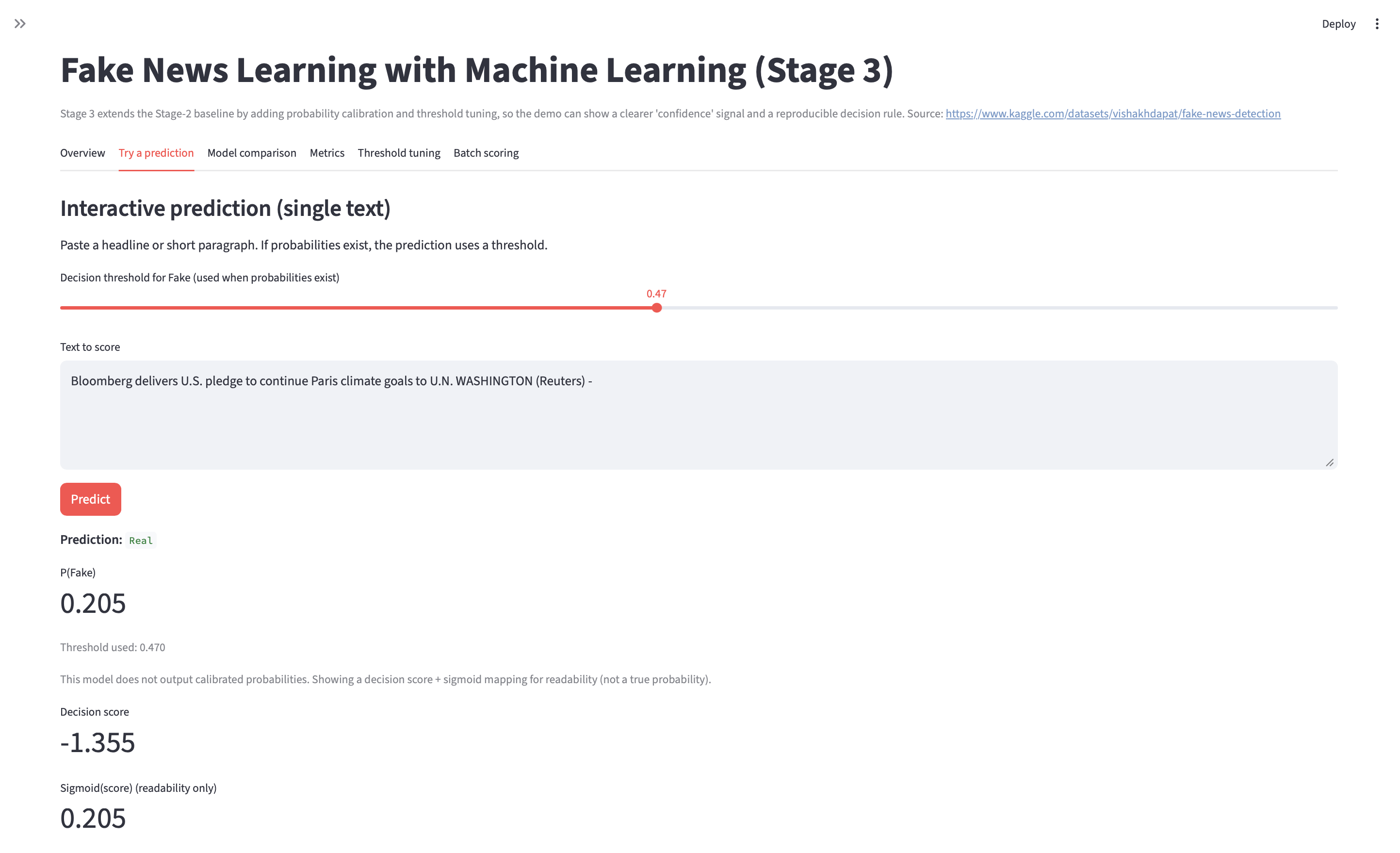
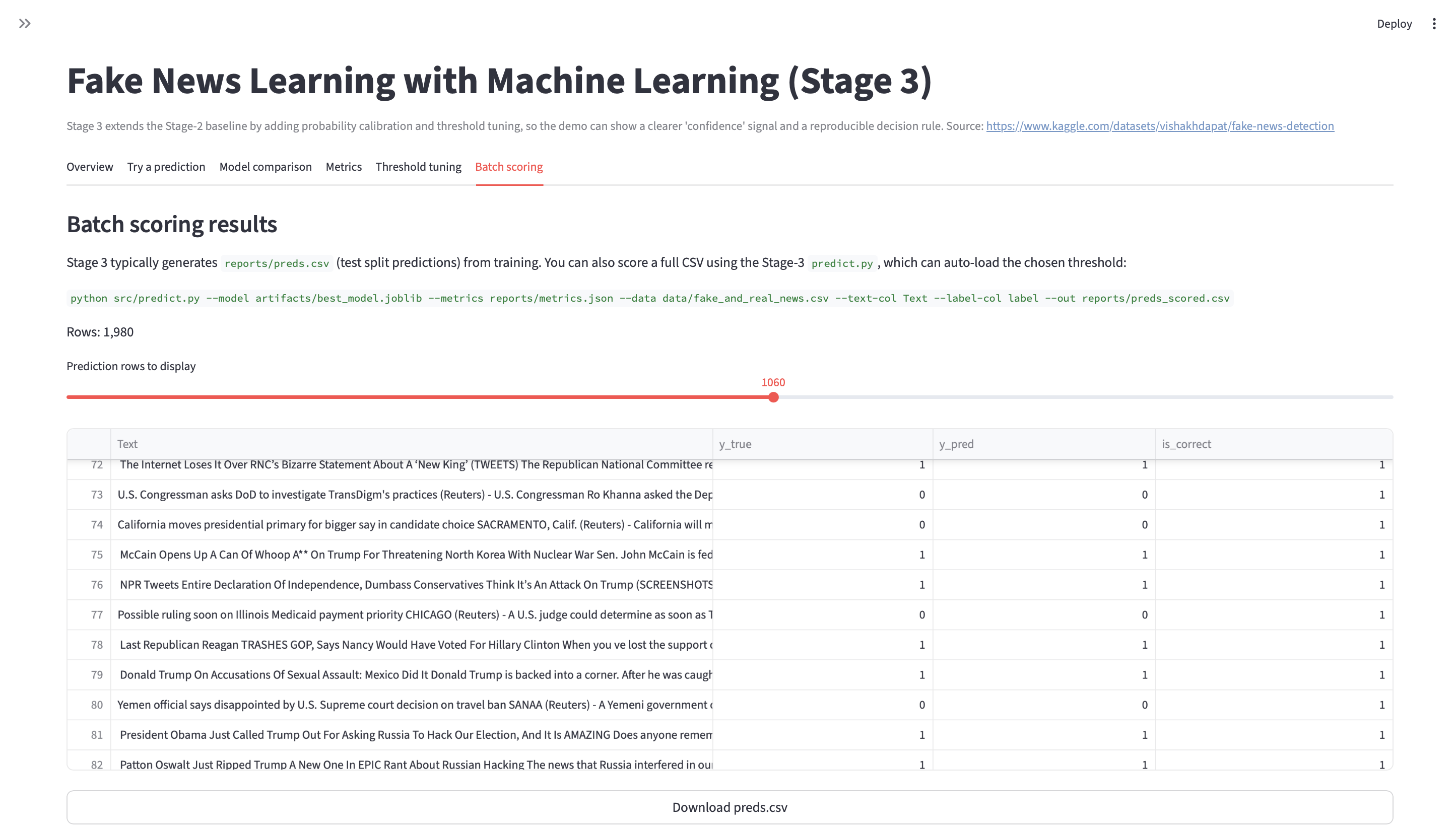
- Stage 3: final metrics + confusion matrix + error review artifacts.
- Re-run flow:
python train.py→python evaluate.py(update to match repo).
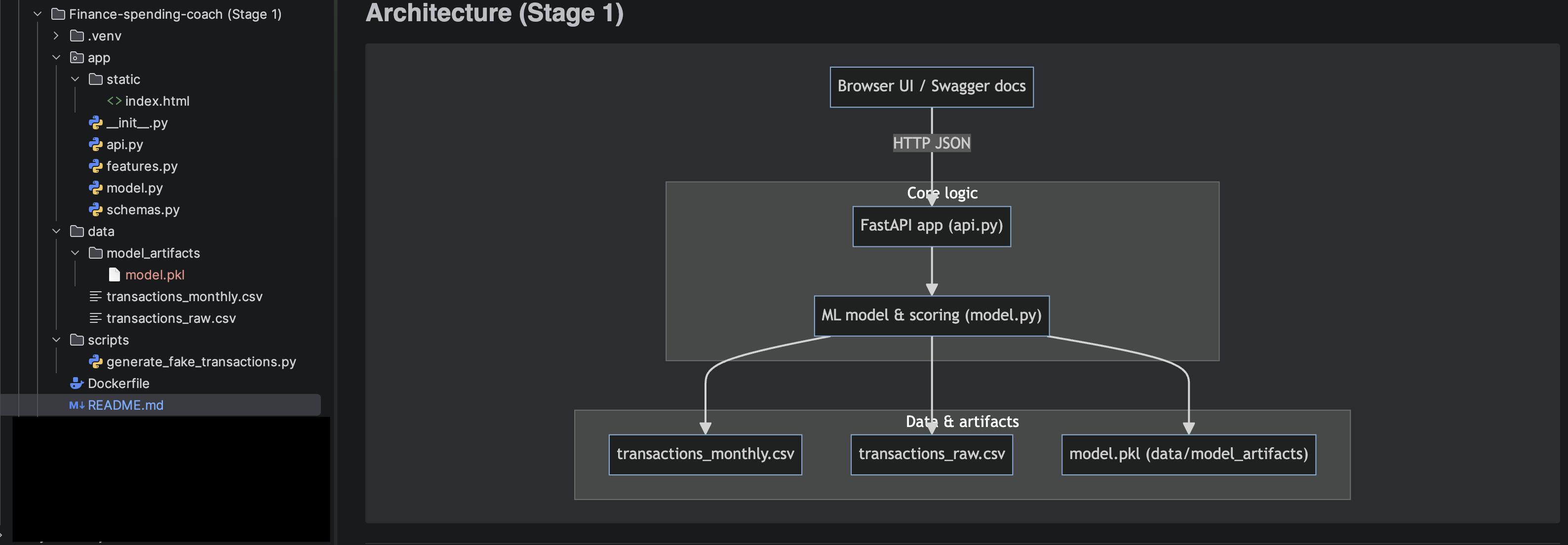
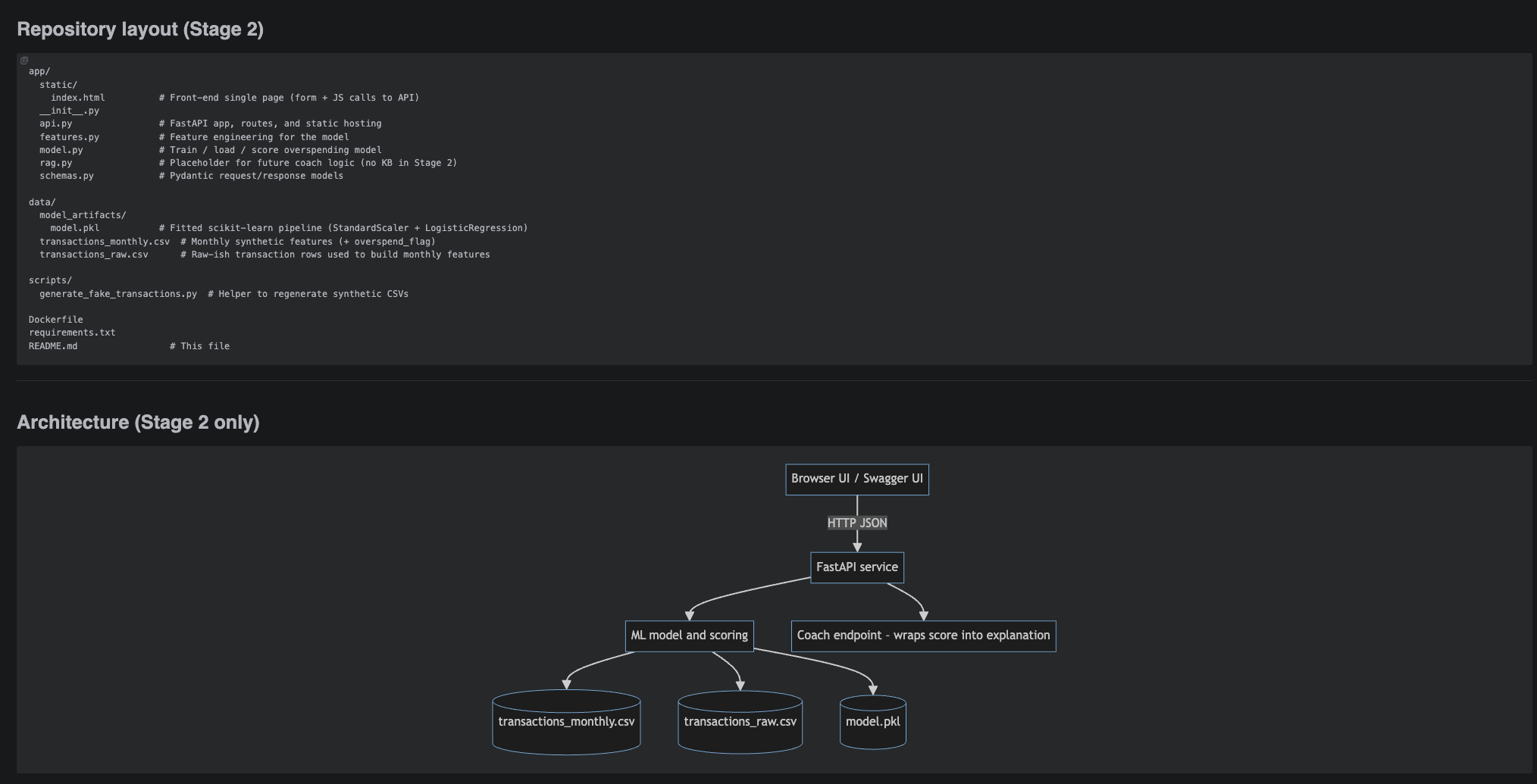
Finance Spending Coach
Three-stage build: scoring API + Swagger (Stage 1), front-end + Docker image (Stage 2), and a Stage 3 AI coach that uses a local Markdown KB and embeddings (RAG) for grounded tips.
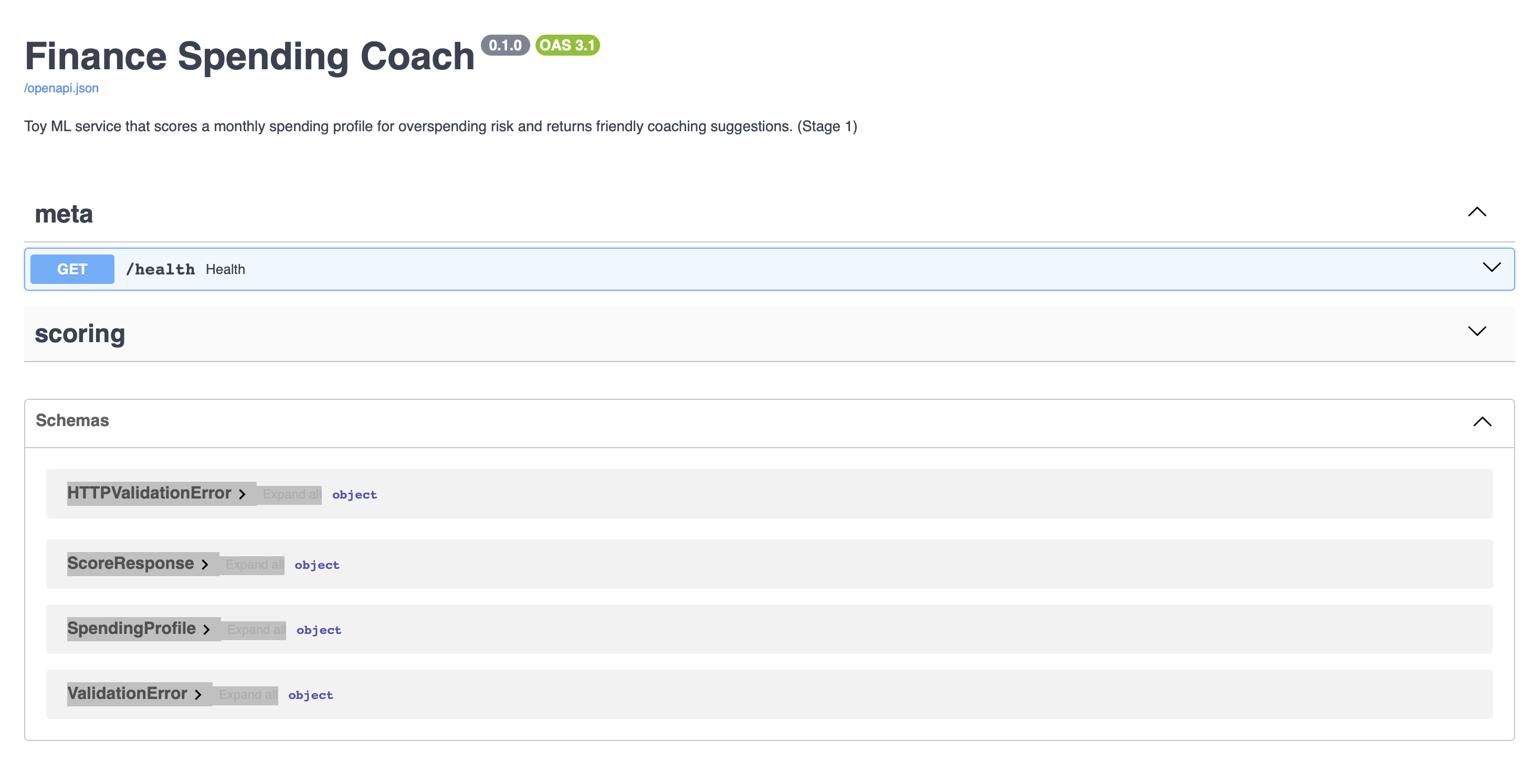
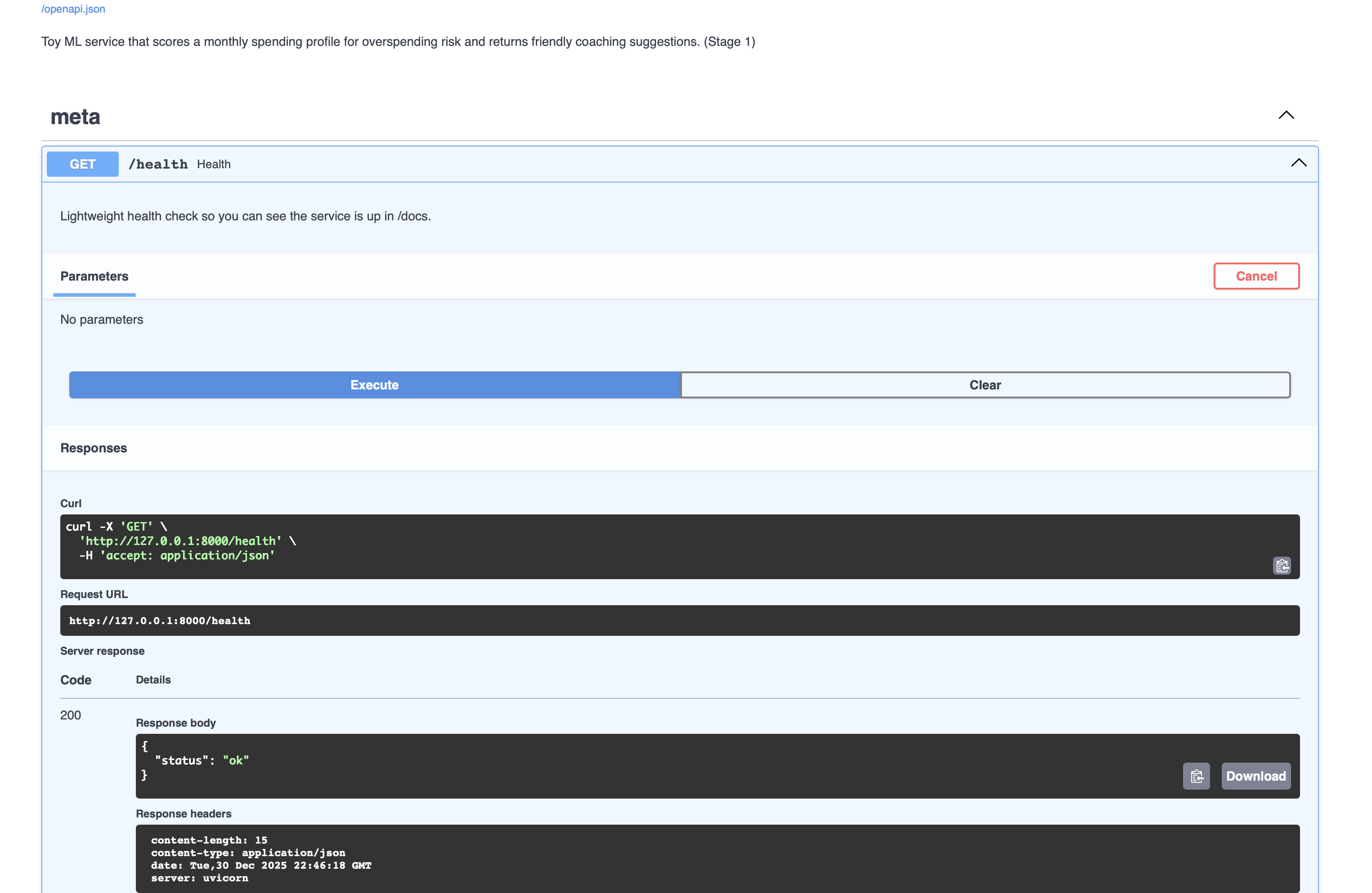
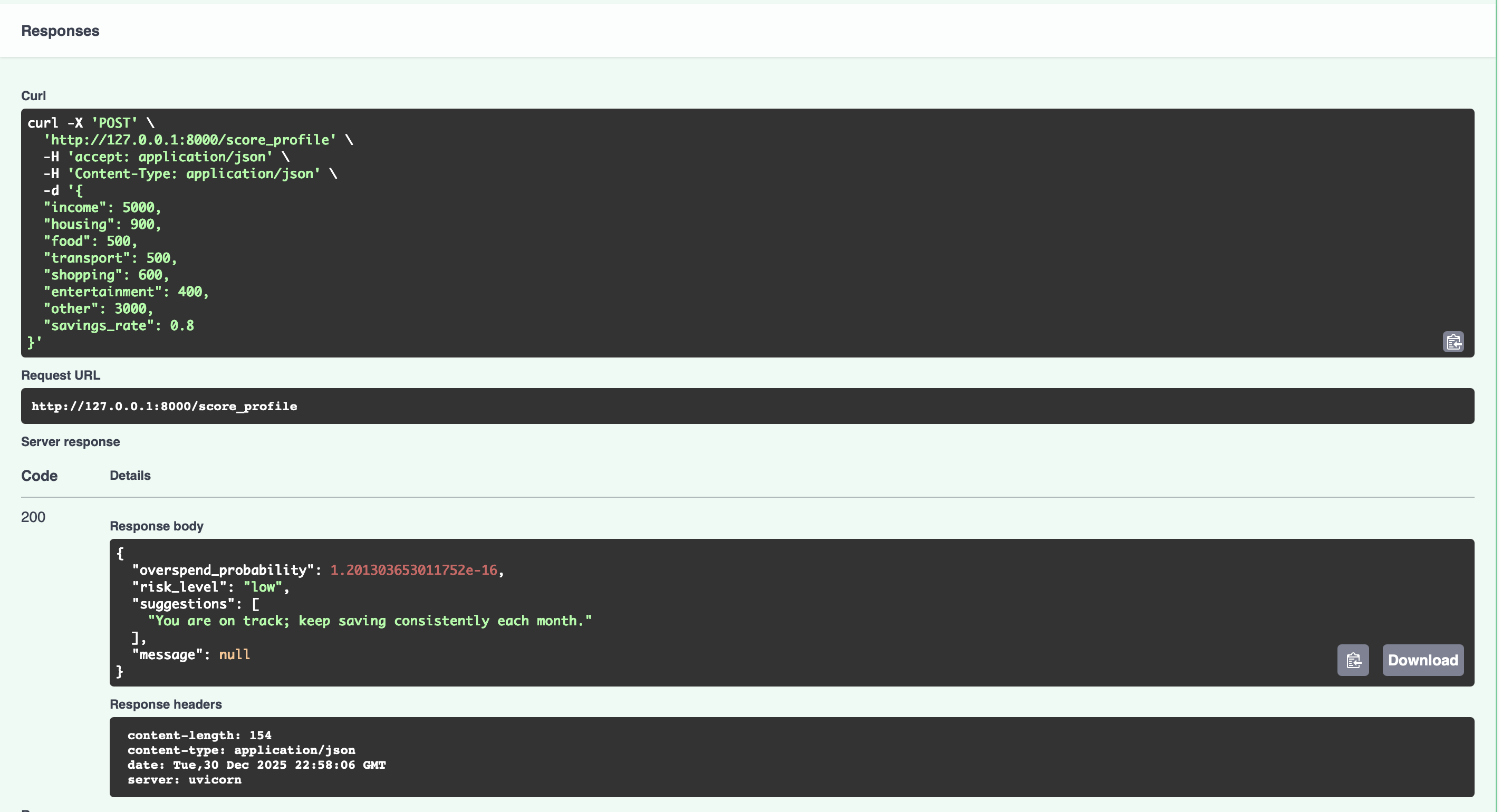
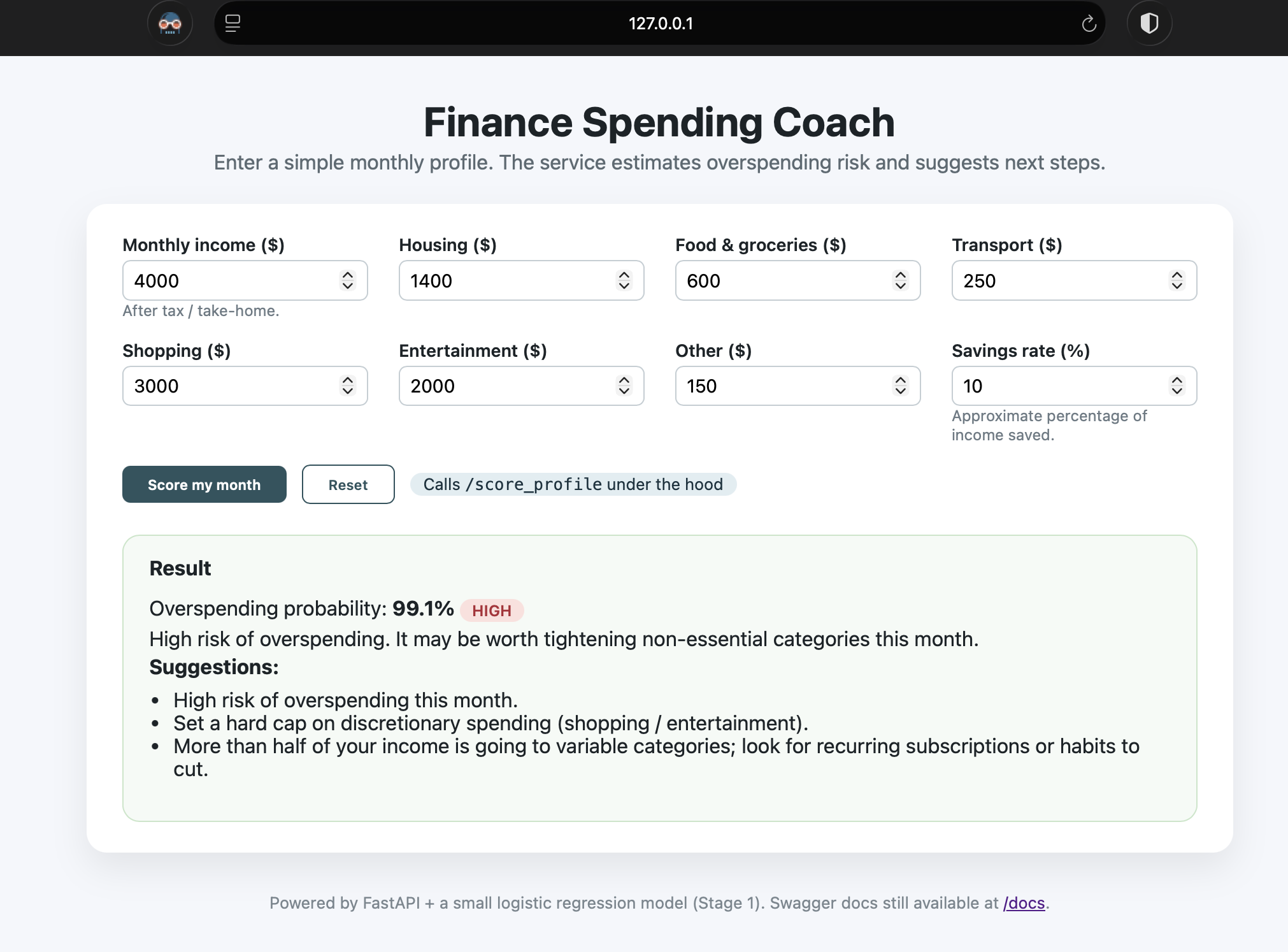
- Stage 1 – ML service: FastAPI + scikit-learn logistic regression that scores a single monthly spending profile and returns overspending risk + rule-based suggestions.
- Stage 2 – Front-end: lightweight HTML/CSS UI that posts JSON to the API, visualizes risk level, and shows “coach-style” explanations on top of the score.
- Stage 3 – Local KB & RAG: markdown budgeting notes are embedded, indexed on disk, and retrieved to ground additional advice in concrete best-practice snippets.
- DevOps: Dockerized service with a one-command build/run flow and auto-generated Swagger docs for all stages.
- Privacy & reproducibility: uses synthetic transactions by default so the project can be demoed safely in a portfolio showcase.
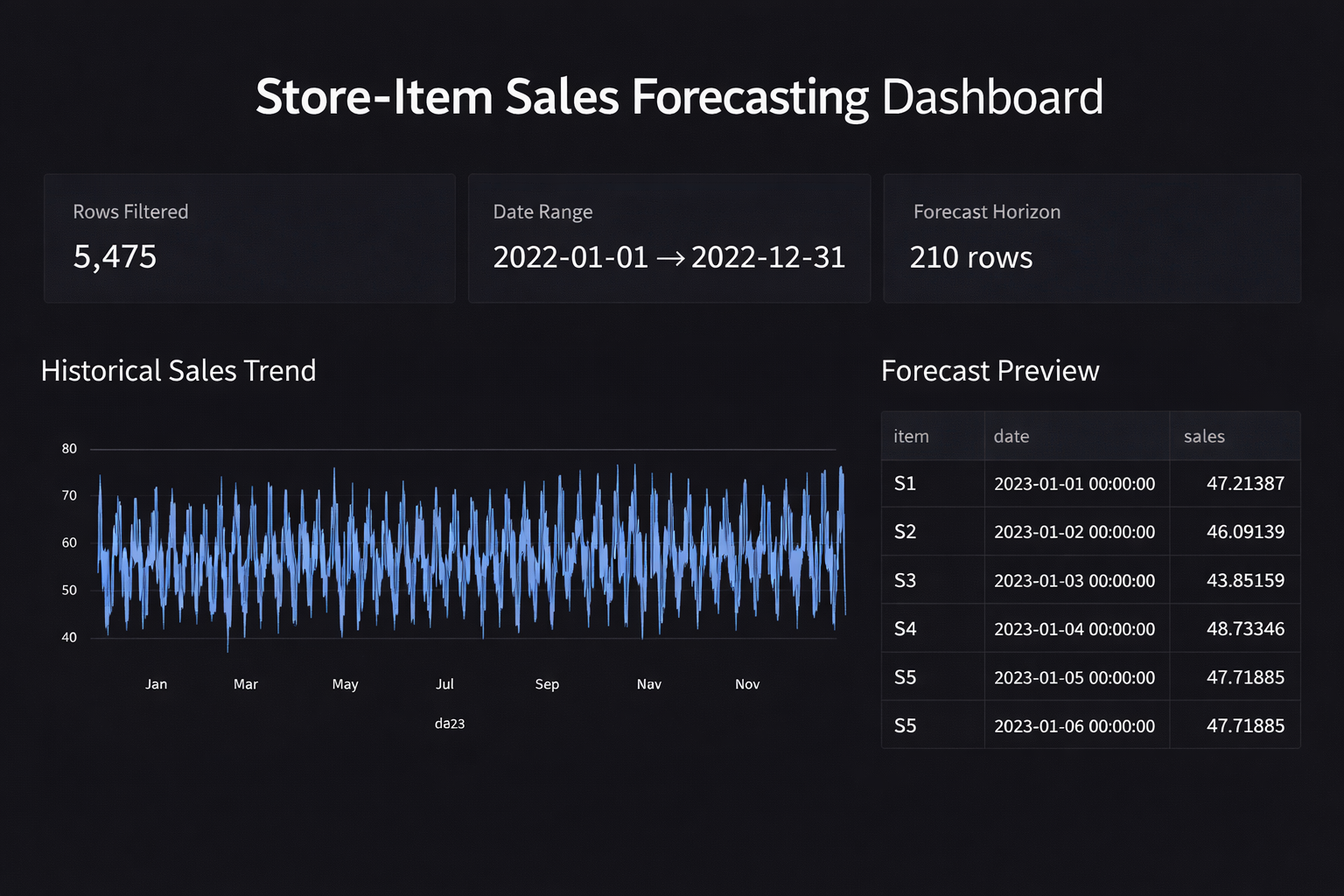
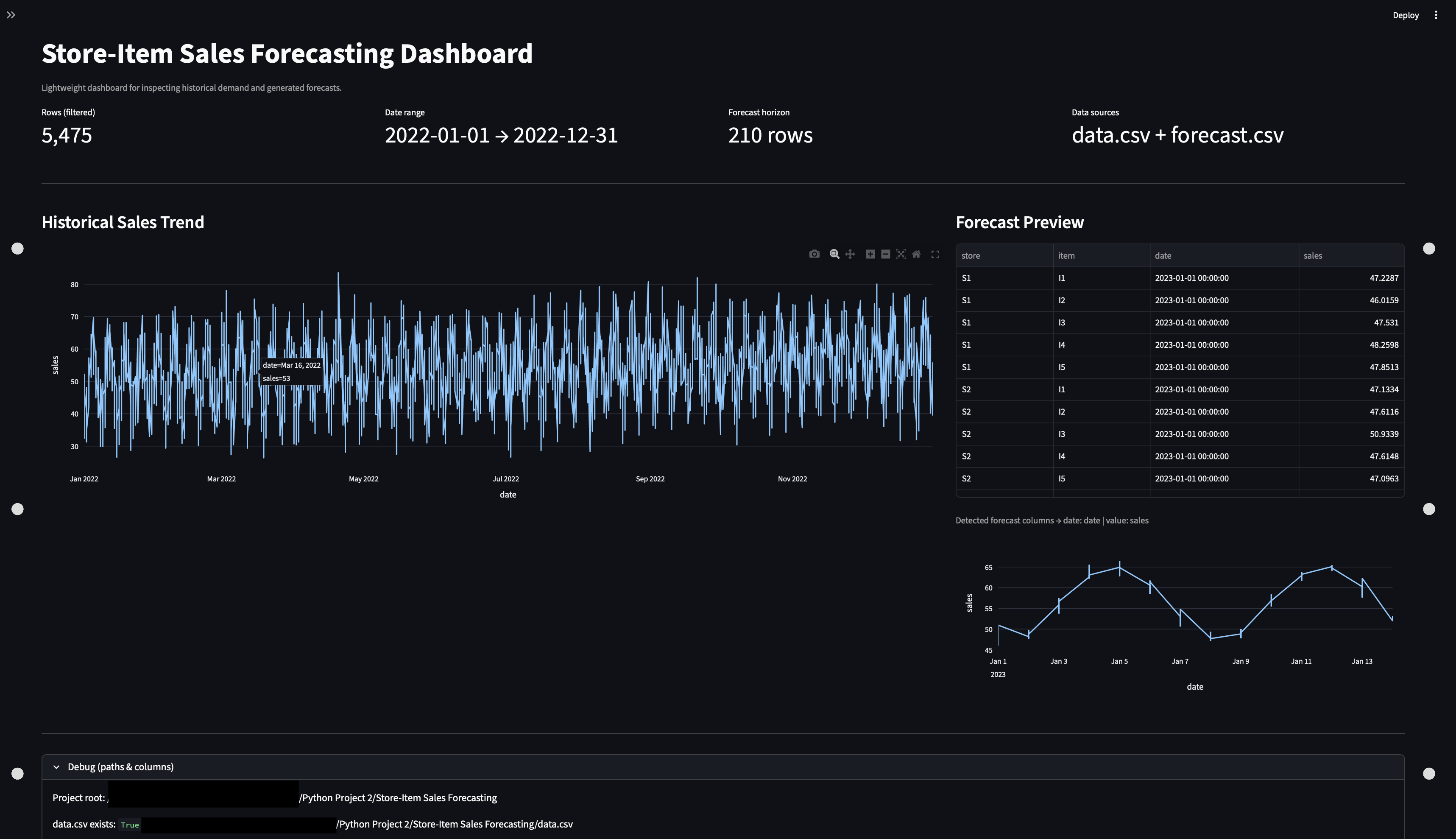
Sales Inventory Dashboard
End-to-end sales + inventory reporting on a synthetic retail CSV dataset created for learning purposes: curated tables, KPI rollups, and trend views with filters for fast stakeholder-style review. Includes reproducible refresh steps and validation checks, with no real customer data used.
- Synthetic CSV dataset (store, item, daily sales, and stock) designed for analysis and learning — no production data.
- ETL/cleanup into curated tables (sales, inventory, product, calendar/time).
- Metrics layer: KPIs (revenue, units, margin, stock coverage) plus trend + breakdown views.
- Dashboard layer with filters and drilldowns via Streamlit.
- Saved outputs: KPI summary tables, charts, and refresh/validation instructions for repeatable runs.